 This special research report sponsored by Tyan discusses practical hardware design strategies for modern HPC workloads. As hardware continued to develop, technologies like multi-core, GPU, NVMe, and others have allowed new application areas to become possible. These application areas include accelerator assisted HPC, GPU based Deep learning, and Big Data Analytics systems. Unfortunately, implementing a general purpose balanced system solution is not possible for these applications. To achieve the best price-to-performance in each of these application verticals, attention to hardware features and design is most important.
This special research report sponsored by Tyan discusses practical hardware design strategies for modern HPC workloads. As hardware continued to develop, technologies like multi-core, GPU, NVMe, and others have allowed new application areas to become possible. These application areas include accelerator assisted HPC, GPU based Deep learning, and Big Data Analytics systems. Unfortunately, implementing a general purpose balanced system solution is not possible for these applications. To achieve the best price-to-performance in each of these application verticals, attention to hardware features and design is most important.
Many new technologies used in High Performance Computing (HPC) have allowed new application areas to become possible. Advances like multi-core, GPU, NVMe, and others have created application verticals that include accelerator assisted HPC, GPU based Deep Learning, Fast storage and parallel file systems, and Big Data Analytics systems.
This technology guide, insideHPC Special Research Report: Practical Hardware Design Strategies for Modern HPC Workloads, shows how to get your results faster by partnering with Tyan.
Workload Design Strategies
Given the variety of today’s HPC workloads, it is important to understand how this maps out to actual hardware platforms. Before considering specific hardware, there is an important design aspect that system designers and users should consider. The PCIe bus is designed for Intel Xeon Scalable systems can be implemented in two ways. Both have advantages and disadvantages depending on your workload.
Balanced vs. Centralized PCIe Topology
Traditional servers have two processors (sockets) with multiple cores and additional memory channels. Memory attached to each processor is shared with the other processor across high speed links. On Intel platforms, these links are called Ultra Path Interconnect (UPI) or Intel QuickPath Interconnect (QPI). In a similar fashion, each processor has a certain number of PCIe bus connections (lanes) that may be shared in one of two ways:
- The first method is the balanced PCIe topology, where a device on the PCI bus may need to traverse the inter-processor links when it is accessed by the processor that is not providing the actual PCIe lanes. This design can create two levels of PCIe access, direct and over the inter-processor link.
- The second method is the centralized PCIe topology, which connects both PCIe buses using a PCIe switch to one of the processors. The unified PCIe bus does not require the interprocessor links and all PCIe access (and device speeds) are consistent to a single processor.
Depending on how the server is used, both methods may have advantages and disadvantages:
- First, consider the centralized PCIe topology, this approach is used in many Deep Learning systems because it allows fast memory movement/access from one GPU to another without the need to traverse the inter- processor links.
- In addition to GPU performance advantages, this architecture can use a lower-end Intel CPU SKU processor with slower UPI/QPI speed at lower cost.
- On the other hand, the balanced PCIe topology for multiple GPU Deep Learning applications creates an uneven GPU-to-GPU memory movement environment that may adversely affect performance.
While the “balanced-root” design may seem less advantageous than centralized-root systems, there are times when separating the PCIe devices may have an advantage. To be clear, all PCIe devices are still visible by both processors. Access to the device may have to travel over the UPI/QPI links. Splitting the “bus” can have an advantage when using GPUs or high speed (NVMe) storage devices to accelerate HPC applications. Since HPC application often relies more heavily on CPU to GPU memory movement or CPU to a storage device, separate PCIe connections can be used to improve performance. There may be cases where assigning processor exclusive access to a subset of GPUs or storage devices can lead to better performance (i.e. By its nature the PCIe bus is a shared bus and segmenting the bus can help with traffic mitigation when multiple applications are using the same server).
Servers for High-IO HPC Computing
Choosing a server for IO bound requires the fastest available storage devices. Currently, solid state U.2 connected NVMe devices can use 4 PCIe lanes and provide a speed of 4GB/s of throughput. Of course the NVMe drive specifications will determine the final performance, but the use of NVMe ensures the fastest connection.
As shown in Figure 1, an excellent starting point for a High-IO computing system is the TYAN Thunder SX GT62H-B7106 platform. As part of TYAN’s leading Intel Xeon Scalable Processor-based storage product line, this 1U server provides many important features for high-IO computing including ten NVMe U.2 drive bays, dual Intel Xeon Scable Processor sockets, large memory capacity, 2 PCIe x16 slots for high performance NICs, IPMI with Redfish support, and (1+1) 800W redundant power supplies. The SX GT62H-B7106 is a good building block for both single node and multi-node storage systems, including parallel file systems and software defined storage.

In addition to the NVMe support, the Thunder SX GT62H-B7106 presents a balanced system where each CPU socket gets its own PCIe x16 slot as well as a handful of NVMe drives (One x16 and 4 NVMe bays for CPU0, and one x16 slot and 6 NVMe bays for CPU1). This design allows for processes running on each CPU to have direct access to high speed networking and local NVMe storage, resulting in the fastest possible access times and the lowest possible latency.
Servers for Big Data Computing
As mentioned Big Data (and database) computing requires both high performance and bulk storage. The best cost-per-byte of storage is still with the 3.5-inch spinning disk drives. The TYAN Thunder SX GT93-B7106 chassis provides a solid platform to create or grow a Big Data computing system. Featuring dual socket Intel Xeon Scalable Processor support with up to 2TB of DDR4-2933 memory, twelve (12) internal easy-swap 3.5” SATA 6G drive bays, one internal 2.5” SATA 6G drive bay, one PCIe x16 OCP (Open Compute Project) v2.0 dual-port LAN Mezzanine slot, one Low Profile PCIe x16 slot, and (1+1) 650W redundant power supplies.

The SX GT93-B7106 has the prefect “simple” design that allows Hadoop, Spark, and NoSQL database systems to deliver solutions using large amounts of data and scale-out or scale-up as needed. Using today’s large 16 TByte drives, a single SX GT93-B7106 has the ability to deliver 192 TBytes of raw storage in a compact 1U platform. By providing options for large amounts of memory and dual Intel Xeon Cascade Lake Refresh CPU, the SX GT93-B7106 can be configured to fit users’ needs. The optional OCP dual-port LAN Mezzanine slot allows for high speed networking to be added if needed to this versatile storage server.
Servers for HPC and Deep Learning Computation
The TYAN Thunder HX FT83-B7119 is a 10-GPU supercomputing system in a compact 4U rackmount chassis. When configured it can support GPU assisted HPC jobs and/or Deep Learning applications.
The base motherboard provides dual sockets for 2nd Gen Intel Xeon Scalable Processors, up to 3TB DDR4-2933 memory, either twelve 3.5” SATA 6G bays or eight SATA plus four NVMe U.2 bays, ten double- width PCIe x16 slots for GPUs, a PCIe x16 slot for a high performance NIC, a BMC with Redfish support, and (3+1) 4800W redundant power supplies.
Depending on application needs, the HX FT83-B7119 is available in four versions based on PCIe bus routing topology and storage options. As outlined in Table 1, each system comes with twelve 3.5 inch SATA bays and two models provide NVMe U.2 support for fast IO in four of the bays (All systems have twelve bays total). Each of these storage options is variable in two different CPU-GPU link topologies.
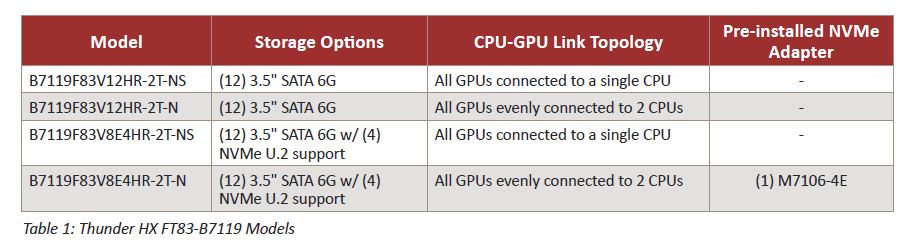
For multi-GPU Deep Learning, all GPUs connected to a single CPU should provide the best performance. In addition, the four bays of NVMe storage are also a good choice because large models may need fast storage for intermediate results.
In terms of HPC, all GPUs evenly connected to two CPUs may provide a better solution if multiple GPU based jobs are run on the system. This configuration will allow multiple conversations to occur over the split PCIe bus at the same time. Recall that memory movement is most important when running HPC applications on CPU-GPU systems.
As interest in Deep Learning continues to increase in traditional HPC, the HX FT83-B7119 is a good choice for both types of applications. With support for Intel Xeon Scalable Processors, a large memory footprint, and plenty of storage, the HX FT83-B7119 provides a great base for many HPC and Deep Learning applications. There is no reason why HPC and Deep Learning applications cannot operate on the same data within the same hardware platform. Figure 3 provides an image of the Tyan Thunder HX FT83-B7119.

Conclusion
In the past, HPC system design was focused on core counts, memory size, and networking. Modern high performance systems can be broken to three basic categories.
- Parallel file systems like Lustre, Gluster, and Ceph require fast balanced storage. In addition, local IO-Heavy computing can take advantage of fast NVMe.
- The need for high density bulk storage of data continues in the Data Analytics market. These systems include Hadoop/Spark and scalable noSQL systems.
- Applications that require accelerated HPC computation include areas such as materials and molecular science, weather forecasting and astronomy, fluid dynamics, financial engineering, oil and gas exploration, pharmacology, and many others. This category also includes Deep Learning systems that are currently seeing high usage in many fields.
Designing for these types of systems requires a thorough understanding of your application space. The following recommendations will provide optimum performance within a given application vertical.
- IO-Heavy applications such as parallel file systems of local IO nodes should consider systems that provide balanced IO from solid state NVMe devices. Consider leading edge systems like the TYAN Thunder SX GT62H-B7106 platform that provides ten balanced NVMe U.2 drive bays, dual socket 2nd Gen Intel Xeon Scalable Processors, and large memory capacity in compact 1U rack-mount system.
- Big Data (and database) computing requires both high performance and bulk storage with spinning disk drives. The TYAN Thunder SX GT93-B7106 chassis provides a solid platform to create or grow a Big Data computing systems with dual socket 2nd Gen Intel Xeon Scalable Processor, up to 2TB of DDR4-2933 memory, and twelve (12) internal easy-swap 3.5” SATA 6G drive bays in a compact 1U rack-mount system.
- In terms of accelerated HPC computing, the TYAN Thunder HX FT83-B7119 is a good choice for a 10-GPU supercomputing system for both HPC and Deep Learning applications. The base system provides dual-socket 2nd Gen Intel Xeon Scalable Processors, up to 3TB of memory, either twelve 3.5” SATA 6G bays or eight SATA plus four NVMe U.2 bays, and the ability to support ten GPUs. The Thunder HX FT83-B7119 provides options to select a balanced or centralized PCIe topology.
In addition to the above mentioned models, Tyan also offers a complete line of leading edge server chassis to build systems optimized for your workload.
Over the past few weeks we explored these topics surrounding practical hardware design strategies for modern HPC workloads and how you can get your results faster by partnering with Tyan:
- Executive Summary, Introduction and Background
- Differentiation in Modern HPC Workloads
- Working Design Strategies, Conclusion
Download the complete insideHPC Special Research Report: Practical Hardware Design Strategies for Modern HPC Workloads,, courtesy of Tyan.

