
Co-authored by Shailesh Manjrekar, Head of AI and Strategic Alliances, WekaIO
As the big data industry continues on an accelerated trajectory, recent experience with large-scale deployments have laser focus for the need of ease of managing petabytes of data in a single, unified namespace wherever in the pipeline the data is stored, while also delivering the best performance to accelerate AI/ML and HPC workloads. Also clear is the demand for data portability across multiple consumption models supporting both private and public clouds with the ability to extend the namespace across both platforms. A cloud-first model delivers the best storage efficiency and TCO across consumption models and data tiers.
In this article, let’s explore what is meant by “data portability,” and why it’s important. Looking at a customer pipeline, the customer context could be a software defined car, any IoT edge point, a drone, a smart home, a 5G tower, etc. In essence, we’re describing an AI pipeline which runs over an edge, runs over a core, and runs over a cloud. Therefore we have three high-level components for this pipeline.
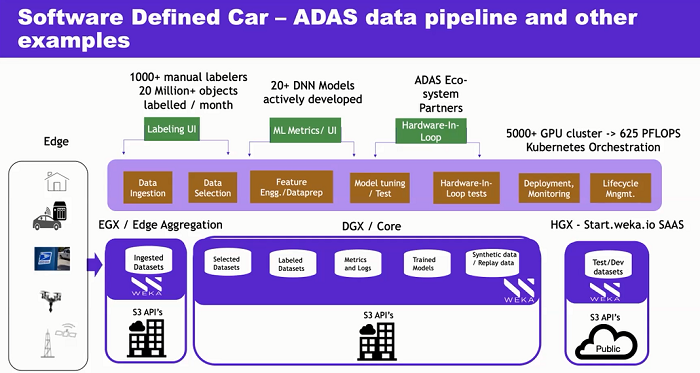
When we say edge, there is actually an edge endpoint, whether it be an autonomous vehicle, a drone and so on. Additionally, there is an edge aggregation point accompanying all of this data. Say it is autonomous vehicles, and ten cars come into a carport, they upload all of their data into that edge. This is the edge aggregation, where part of the data processing happens, which in AI/ML terms is called inference.
Then there is the core which is all about the training of the neural nets. And lastly there is a cloud which is all about using economies of scale, leveraging the cloud’s technology lead with all the frameworks, etc.
Limitations of Data Portability
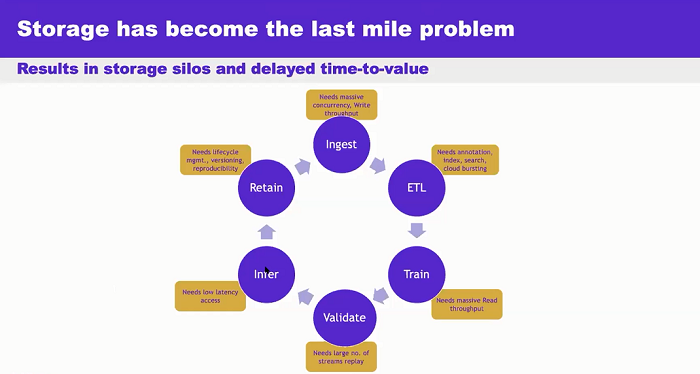
There are a number of data portability limitations to consider. If you were reviewing a variety of technology solutions, say for example a NetApp solution or an EMC solution, there will be one storage system catering to the edge aggregation requirement, there will be another storage system catering to the core requirement, and then there will be yet another system catering to the cloud requirement. This strategy results in storage silos, and corresponding delayed outcomes.
A better strategy is a software defined solution that’s not tied to any particular hardware, where you can deploy on an edge, where an “edge” could be something like an edge gateway, or an edge supercomputer, or an edge GPU computer like NVIDIA EGX Server (where DGX is used in the data center, EGX is used at the at the edge).
This is an example of how a customer could deploy WekaFS at the edge aggregation. WekaFS doesn’t go on the edge endpoint, but instead on the edge aggregation. Similarly WekaFS can be deployed in the core, again not tied to any hardware. It could be SuperMicro hardware, it could be HP hardware, or it could be any white box hardware from any storage OEM. Weka works with a big ecosystem of OEM partners, all leading-edge storage vendors, and Weka also works with cloud players like AWS.
Alignment of Deployment Models
The key thing to note is that an optimal strategy is for the software loaded on each deployment model (software bits) to be exactly the same, whether you’re deploying it at the edge, or whether you’re deploying it at the core or in the cloud. That by itself lends a big advantage to this approach, as it is abstracting the underlying hardware, whether you’re deploying on an edge gateway, whether you’re deploying on anybody’s hardware, or you’re deploying in the cloud. The look and feel, the performance characteristics you are going to get out of the deployment is going to be exactly the same.
The result is going to be very high performance, low latency, coupled with the ability to handle mixed workloads, the ability to do data management across this edge-core-to-cloud, because of the ability to talk to the back-end S3 buckets. That bucket could be at the edge, that bucket could be in the core, or it could be in the cloud. The appeal is that data mobility, and the orchestration aspect is also built into the filesystem, as it spins up optimal S3 connections for gets/puts to object storage.
In addition, all of this works typically in a Kubernetes environment. Kubernetes does the orchestration for the front-end, or for the compute portion, or for the applications. But along with those applications moving across the edge-to-core-to cloud, you also need the underlying data store, which is where the persistence comes into the picture. Every application has some level of persistence and statefulness to it, and that statefulness also needs to move from wherever the deployment moves, and that is what Weka brings to the table – that ability to provide that data anywhere capability, whether you are deploying at the edge with a core, in the cloud – it complements Kubernetes. That is what is meant by data portability.
Mixed Workloads
Handling of mixed workloads is a step in the right direction. Whether you are doing data ingestion, or whether you’re doing some ETL processing – this is a typical AI data pipeline. At a storage IO level, when you’re running such a pipeline on top of a storage system, each of the phases has various (weighted) storage requirements. Maybe you’re ingesting data, or maybe you’re doing some ETL processing, where you’re labeling that data set, etc. Maybe you’re training, which is all about massive read bandwidth. Maybe you’re validating the neural net models, which is all about streaming performance. Then you’re doing inference which is all about low latency. Then you go into Lifecycle Management. More than likely, if you weren’t using Weka, the result is a lot of storage silos, because if you look at any other storage vendor’s portfolio, you’d see that their storage is optimized for one or two of those phases, not the entire lifecycle. Weka is uniquely able to cater to the entire life cycle. That is Weka’s strength in the marketplace.
Weka Software Defined storage solution
Weka Software Defined storage solution enables workload portability, a hot topic moving into 2021. WekaFS is recognized as a legacy NAS alternative, and is an extensive cloud offering, a high performance storage-as-a-service, which is garnering a lot of traction in how it brings out Weka’s data management capabilities. Cloud deployment, even before COVID-19, is becoming a critical storage strategy for managing data centers not only in terms of flexibility and agility, but also for workload portability.
In addition to this pipeline, this is also clearly an AI use case. Also in reference to the data portability aspect is Weka’s ability to host a business intelligence application, e.g. SAS analytics. Another kind of application is an AI application on the same platform. And the third kind of application is a cloud native application such as a NoSQL database like Cassandra. This is another example of how we talk about data portability. It doesn’t matter what the application is, it’s a single storage layer, which can cater to all of your requirements in terms of data.
Be sure to check out previous articles by Weka: HPC-Scale Data Management for the Enterprise that’s Easier and More Cost-Efficient than NAS

