[SPONSORED CONTENT]
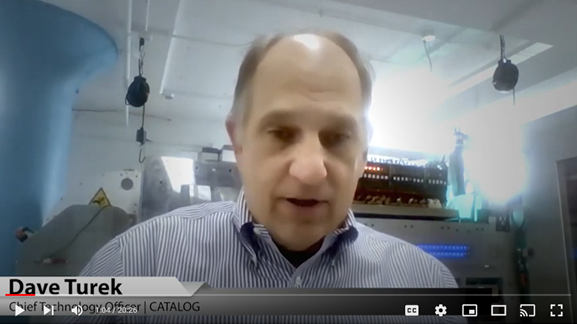
Dave Turek is one of the venerable names in HPC. Having long served at IBM in senior strategic roles, he has spent decades at supercomputing’s leading edge. In 2020, Turek joined a Cambridge, MA company called Catalog, a venture-funded startup immersed in the emerging and exotic world of DNA-based data storage and compute.
In this interview conducted by insideHPC on behalf of HPC industry analyst firm Hyperion Research, Turek explains the basics of DNA-based technology, its performance characteristics, initial workloads and markets to which it’s expected to be applied and a timeline for commercial viability.
According to Turek, DNA-based technology has a tremendous dual-potential to deliver long-term, highly stable and dense data storage along with, on the compute side, extreme high performance at low energy consumption. Turek, who is Catalog’s CTO, hastens to add that the DNA produced by Catalog is strictly synthetic, it’s not biologically active and therefore not an environmental threat.
Interview Transcript:
Doug Black: Hi, I’m Doug Black, editor in chief at inside HPC, and today we’re talking on behalf of Hyperion Research with Dave Turk, he is chief technology officer at Catalog, which is a Cambridge Mass.-based startup involved in synthetic DNA-based data storage and computation. Dave, welcome.
Dave Turek: Thanks Doug. Nice to be here.
Black: Why don’t we start with some basic definitions — what is synthetic DNA and its use in storage and compute; give us a basic understanding of how you store data in DNA.
Turek: By synthetic DNA, we mean DNA that we manufacture in the laboratory, it’s not the DNA that you’re going to find in a living organism. And by virtue of doing that, we can actually control and make sure that the DNA that we construct is not biologically active. Essentially, we put stop signs in it, and you really can’t take those out. And you couldn’t do anything with the DNA that we’re working with to make it be biologically active.
![]() All right, now to code data into DNA we have to have some sort of scheme to relate data to the molecule in DNA. And the approach we take is very much an approach akin to stacking Lego building blocks, if you will. So imagine you have a box of Lego pieces, they’re all the same size, and of course everybody understands Legos, you can take them and stack them on top of each other. But now imagine the Legos all have different colors, so you reach in, you take out five pieces, you create a stack on top of each other, it’s red, yellow, green, blue, white. You reach in again, you create another stack of five pieces, except now it’s purple, black, brown, green, pink. And just by inspection, you could look at and say, ‘Well, I’ve got two stacks, they look kind of the same, they’re the same length and everything. But I can tell they’re different because they’re different colors.’
All right, now to code data into DNA we have to have some sort of scheme to relate data to the molecule in DNA. And the approach we take is very much an approach akin to stacking Lego building blocks, if you will. So imagine you have a box of Lego pieces, they’re all the same size, and of course everybody understands Legos, you can take them and stack them on top of each other. But now imagine the Legos all have different colors, so you reach in, you take out five pieces, you create a stack on top of each other, it’s red, yellow, green, blue, white. You reach in again, you create another stack of five pieces, except now it’s purple, black, brown, green, pink. And just by inspection, you could look at and say, ‘Well, I’ve got two stacks, they look kind of the same, they’re the same length and everything. But I can tell they’re different because they’re different colors.’
We essentially do that with DNA, except instead of having Lego building blocks, we create these pre-manufactured synthetic pieces of DNA called oligonucleotides. They’re very, very small compared to the kind of DNA you would see in a person, 20 or 30 base pairs compared to 3.5 billion. And we take these things, and we essentially stack them on top of each other. The stacking process in DNA is called ligation, and we’re stitching them together, if you will, chemically, and by virtue of doing that, taking small pieces, connect them together in a prescribed way to create a longer piece.
That longer piece, which we refer to as an identifier, carries with it two bits of information. It represents, first of all, an address in a bitstream of data. And secondly, it tells you whether the value at that address is a one or a zero. So going back to my Lego example, if we look at our five Lego stacks – red, yellow, green, blue, on one hand, and brown, purple, black, white, pink, on the other hand – the first one might be the address 2335 in the bitstream, and the second one might be the address 1,235,654 in the same bitstream. The first one might have a value of one, the second one might have a value of zero. And this is what we do with DNA.
Now in back, and you can see this in the screen, is the machine that we invented to automate this process. So we actually build these stacks of DNA at a rate of more than 500,000 per second — 500,000 chemical reactions per second — creating, if you will, stack models of DNA that comprise the information that dictates either a one or a zero in a specific address in a bitstream. So overall, you’re operating in megabits per second and terabits per day. And this is just a prototype machine, a machine design to explore the scalability and other limiting factors of manipulating DNA.
Black: So tell us about the initial markets, the workloads, the use cases, that Catalog is targeting?
Turek: Well, if we begin by talking about why DNA it’ll begin to give us some idea of the markets that we’re trying to attack. So we’re using DNA because it’s about a million times more dense in terms of data storage than conventional storage media. That’s a huge savings in terms of overall costs.
The second thing is it never goes obsolete. So if you go in on new generations of tape (storage), periodically, you know there’ll be innovation. Two years down the road, you’ll have to do migration, you may have to get new equipment, etc. And if you wait too long with the technology, (it) might become obsolete simply because of the lack of support, in terms of device drivers, operating system and so on.
DNA molecules are forever. If we encode some data in a DNA molecule today, 100,000 years from now it’ll still be a DNA molecule, it’ll still be readable, so there’s no obsolescence involved in what we have here.
And then the last thing is, it really takes very little energy. Once we, encode data into a molecule, we can desiccate it and put in a little test tube (that) would probably hold the entire contents of the Library of Congress, and it doesn’t require any energy to preserve it, it will just sit there on the shelf, and 1000 years from now you can pick it up and you can operate on it.
So with that in mind, of course, people naturally jumped to the idea of: wouldn’t this be a great cold storage or archive kind of capability. And that’s true. Our ambition is a little different. What we want to do is to encode the data into DNA, but we want to do it in a way that permits active storage. So not that you simply have data sitting in a test tube on your shelf, but we think we can compute on DNA-encoded data with additional DNA that we would put into something like this and actually do search queries, do compute, do many of the things you can do with conventional computers, but do it in a very low energy, low density, low cost kind of model.
Black: On the power consumption topic, tell us about the relative power consumption between a DNA storage system and its equivalent disk or tape — traditional storage tape-based system in terms of watts, terabytes per watt or other metric. And what use cases are there (that have) no power consumption with a DNA based system at all?
Turek: The range in energy savings will vary anywhere from one to two orders of magnitude, in terms of conventional technologies. And when I say conventional technologies, I mean tape, disk and compute bundled together to facilitate the storage of data, the retrieval of data, some analysis of the data. The exact breakdown in terms of those categories remains in the discovery, but we’ve done some calculations that suggest we’re in the one to two orders of magnitude difference from those kinds of conventional technologies.
Domains where energy is simply effectively absent is when you have passive storage, and you’re just putting data into DNA, maybe desiccated in the kind of test tube I showed you, and you can put it on a shelf somewhere and it just sits there, no energy required. The amount of energy required to retrieve it is going to be fairly slight. And the amount of energy required to compute on it will be a function of the nature of the way you compute.
But here’s an interesting thing about DNA and about DNA storage. You have to suspend the idea of file structures driven by physical media that we have today. So for example, with tape, data is encoded serially on the tape device. And so if you want to find the 5 millionth bit in that volume of tape, you have to go through the first 4,999,999 bits before you get to it. So in that sense, electronic storage has difficulty scaling as data grows because the more data you have, the more you have to search sequentially, or through an index scheme from source, to get to the data you’re targeting.
In a DNA world, we can do that effectively with just one chemical operation. So data is not stored in a physical structure the way you think about electronic media, but it’s actually a pool of data in a liquid. Think of a flask with a bunch of DNA and liquid in it. If I want to find a particular piece of data in that, I’ll simply inject a probe into that fluid, and it’ll come back and we’ll find the particular piece of data that I’m looking for. It doesn’t have to search it in any sort of prescribed way. It’s a huge advantage in terms of speed, but there’s also a huge advantage in terms of the amount of energy consumed. I don’t have to search through billions of bytes of data to find what I’m looking for sequentially. And I can just go directly to the target with tremendous savings in time and energy.
Black: Fascinating. So when does Catalog expect to have a commercially viable DNA-based compute platform on the market?
Turek: We’re targeting anywhere from two-and-a-half to three years from where we stand today. Of course, we have to master the issue of data encoding first. And then we have a number of projects currently underway to look at computation against that data.
Computation is nothing more than the transformation of stored data to create a new form of information not directly represented in the stored data. So for example, if you take two matrices and multiply them together, you create a new matrix. That’s the output of the computation. We have about seven or eight different computation projects going on today that we think will show up in areas like digital signal processing for your transforms, we have the ability to create logic gates into Boolean operations, we have the ability to do branching kinds of computations as well – ‘if, then, else,’ these kinds of things. We have the ability to operate on graphical representations of data as well.
And we think the amalgamation of these different approaches will open up a tremendous set of opportunities in a variety of different market segments. We have, for example, spoken to people who are operating in seismic processing where techniques that you might see reflected in digital signal processing are appropriate. We’ve talked to people who are doing inferencing against image files and audio files. Again, the invocation of transformed kinds of capabilities embedded and things like digital signal processing become important.
We would expect by the end of 2022 to have a demonstration of a computational approach to a serious problem in hand at that time. By serious problem, I mean a significant amount of data, a computation that has value at a cost point that people can look at and discern whether it presents value to them or not.
Black: Okay, great. Now, Catalog has put out information and announcements and so forth that states that Shannon, which is your DNA writer, is capable of thousands of chemical reactions per second. How does that performance metric translate into a compute or data storage performance metric that HPC users, architects and data center managers can relate to, such as FLOPS, job run time, terabytes per second, IOPS or latency?
Turek: With respect to storage first, the machine as it’s currently designed — which is nothing more really than a prototype machine to help us explore problems of scalability and so on — produces about 500,000 so called “reaction spots” a second. Each one of those reaction spots is a location where this building of a longer DNA molecule takes place. So: 500,000 per second.
Now, we have the ability to put in error correction here as well, because there could be a misfire or something like that in the compositing of the DNA and the location that’s of interest to us. But currently, this machine is calibrated to be able to produce about a terabyte of data per day. So per se, that’s not competitive with conventional technologies. But remember, this machine is not a commercial machine. This is a machine designed to help us explore limits, design parameters and other environmental kinds of issues that we can scale up.
It turns out the machine is predicated on the use of inkjet printer technology. In back of me you can see some aspects of that. We actually can begin to expand the performance of the machine exponentially by the addition of individual additional inkjet printheads. So the nature of the way we’ve architected the system says that the growth of performance is exponential as we add more so-called “processing elements.” For us the processing elements is an inkjet printhead with a number of nozzles in it as well. So if you go from let’s say 30 printheads, which is what we have today, to let’s say 100 printheads, which is well within the realm of possibility, it’s going to be a many, many orders of magnitude increase in the amount of data that could be stored. That’s the storage part of the equation.
The computation part of the equation is a little more nuanced to really talk about because it’s unclear whether or not we want to talk about this in terms of conventional FLOPS and OPS and things like that. I think the dimension that we want to put attention on to is the extraordinary degrees of parallelism, and help people understand the way in which a chemical operation takes place in contrast to a compute operation.
So for example, in a compute operation, it may be an imperative where you talk about “do A, then do B, then do C, then do D.” For us, it’s more declarative. We would take this amount of data that we have in a liquid, and we would simply drop a collection of probes into it to begin to execute the kind of functionality that we’re trying to represent from a computational perspective. The translation may not be as direct as anyone might like. But at the end of the day, what we want to do is measure time to insight, that’s the fundamental criteria.
So if we can invoke degrees of parallelism to go many orders of magnitude beyond what you could do with a conventional supercomputer, and we can by virtue of that dramatically reduced time to insight, those other parameters are not as expressive in terms of what we’re trying to accomplish as the time to insight dimension.
So it’s start the activity and end the activity – how much time was required? What was the cost of getting from point A to point B? And we’ll publish more on that during the course of the coming year.
The coming year is all dedicated to putting some real meat on the bones of what we’re talking about here as we move from the theory that we’ve been working on in the last year to the implementation of practical representations of both storage and compute that we talked about today.
Black: OK, very exciting stuff. Catalog has put out an announcement that references automation as a key feature. Can you share how automation is a differentiator for DNA-based technology and for Catalog?
Turek: Much of the theory behind DNA storage is reflected in the literature in terms of what we would call benchtop chemistry, where under very precise conditions laboratory chemists are effectuating the encoding process that they adopt. What we’ve done is we automated all of that. And the reason we did that is twofold. One is, you want to ascertain whether or not this is commercially viable. And it’s very hard to extrapolate from benchtop experiments the kinds of problems that you would see if you tried to elevate things to a commercial level. In other words, doing it one or two times doesn’t necessarily give you a clear indication of what happens if you do it 20 million times.
The other thing that automation has done for us is present consistency in the approach. Benchtop chemistry is fraught with subtle differences — day to day, person to person — that may provide compounding kinds of data from the experiments you’re running and the conclusions that you draw. By automating, we get a process that’s more controllable and gives us greater insight faster in terms of any anomalies we might see, as well as allowing us to explore the limits of what the possibilities are.
Black: David, lastly, describe what you mean, what Catalogue means, by “portable DNA computing platform”?
Turek: Well, as you can see in back of me here, the machine we have now is fairly sizable, it’s in the shape of an L. One leg is maybe 13 feet, the other is 10 or 11, something like that. We’re not portable. But what we want to do is miniaturize everything, we want to make use of microfluidics, we want to reduce the amount of chemistry involved by at least three orders of magnitude. We want to explore laboratory-on-a-chip kinds of constructs. And ultimately, we can easily see ourselves getting this down to a desktop kind of unit, or maybe even making it completely portable where you can operate both in terms of data storage, data manipulation and compute in an environment that’s untethered from the kind of infrastructure that we have here today.
That’s well within reason. We’ve already begun to explore ideas like that. And I think that as we get settled on the nature of the compute paradigms that we want to implement we’ll start using that to inform the way we want to pursue this notion of miniaturization of the overall process.
But you can expect a process that’s desktop in size, that the chemistry is almost invisible to you because the volumes are so low, and the performance and the energy consumption will be off the charts.
Black: Thank you, David. I’m Doug Black of insideHPC, on behalf of Hyperion Research, thanks so much for being with us today.
Turek: Thank you.

meat on the bones. ok great, could you be a little more specific? I mean time to insight is cool but geezus Dave, illustrate this a little better. parallelism to solve what problems, and how?