
Large language models fit the classic model of a red-hot technology in an early stage of commercial viability: there’s more talk about it than knowledge, and FOMO – the fear that your competitors are implementing it at your peril – is helping to drive explosive demand. There’s also an allure and mystery around LLMs: some of the awe-inspiring “zero shot” things they do surprise even the data scientists who trained the models (more on this below).
Against this backdrop, Bob Sorensen, senior vice president of research at industry analyst firm Hyperion Research, presented at the recent HPC User Forum in Tucson on the state of generative AI and LLMs.
On market demand for large language model solutions, Sorensen cited a new Hyperion survey of HPC end users in the U.S. and around the world across commercial, government and academic verticals. Fully 96 percent said they are currently (58 percent) exploring LLM potential for existing HPC-based workloads or plan to (48 percent) over the next 12 to 18 months.
Sixty-two percent said they are currently procuring access to LLM software or will over the next 12-18 months, while 65 percent said they are reaching out to LLM hardware and software suppliers for information or plan to within 18 months. Twenty-two percent said they are running LLM-enabled workloads while 50 percent said they will within a year-and-a-half.
While there’s debate whether HPC and AI are separate entities or if one is a subset of the other (see Why HPC and AI Need One Another from UK managed services company Redcentric), LLMs can’t be trained or run without HPC-class resources.
Credit: Hyperion Research
Sorensen cited several examples of big tech companies’ LLM HPCs, including Google’s A3 VM HPC, which utilizes 26,000 NVIDIA H100 GPUs in a single cluster delivering 26 exaFLOPS of AI performance, the Microsoft/OpenAI HPC that cost hundreds of millions of dollars and utilizes 285,000 AMD EPYC Rome CPUs and 10,000 NVIDIA A100 GPUs, and Meta’s Research SuperCluster (Phase 2) comprised of 16,000 A100s and one of the largest known flat InfiniBand fabrics with 48,000 links and 2,000 switches.
Then there’s the NVIDIA DGX Cloud with 640 GB memory instances and priced at $36,999 per month per instance.
![]() “The computational requirements are absolutely horrendous or aggressive or astounding, whatever term you like,” Sorensen said.
“The computational requirements are absolutely horrendous or aggressive or astounding, whatever term you like,” Sorensen said.
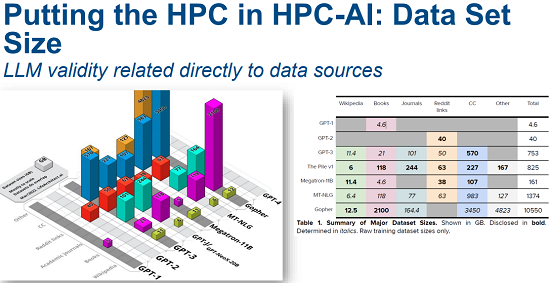
These resources are needed to handle the enormous data volumes and parameters encompassed by large language models. Typically, models are initially trained on large amounts of publicly available data, such as Wikipedia, Common Crawl, Project Gutenberg, OpenWebText (a collection of more than 40GB of text from the web pre-processed to remove low-quality text), Reddit and Cornell Movie Dialogs Corpus, a data set of movie scripts and conversations used for conversational training.
LLMs are then typically directed at a focused field and a defined task.
“The key here is that you train (LLMs) on broad data, the foundational model aspect of it, and then you do fine tuning to specialize them in some way,” he said. “You take a very intelligent being that doesn’t really know a lot of details, and you give it some smarts in some particular area. And then you have a very fine-tuned model, whether it be for the legal profession or … the scientific world or entertainment, (and train it) to answer questions, talk to customer and to service clients in a relatively intelligent manner.”
Credit: Hyperion Research
Model sizes are comprised of tokens, the basic units of text (words, numbers, punctuation marks) or code used by an LLM. Token size is a measure of how much data was used to train the parameters. Also called weights, a token is a connection chosen by the LLM and learned during training. They are then used to infer, or generate, new content.
Here’s where scale really kicks in. “The larger the number of tokens, the more nuanced is the model’s understanding of each word’s meaning and context,” Sorensen said, resulting in LLM using 100-200 billion tokens.
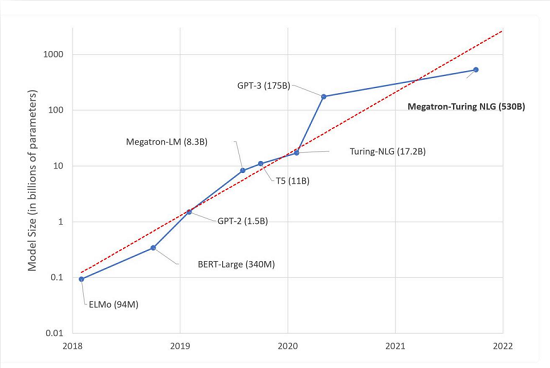
He cited the famous example of the Megatron Turing NLG (natural language generation), with 530 billion tokens that was trained on NVIDIA’s DGX SuperPOD-based Selene AI supercomputer, currently ranked no. 9 on the TOP500 list of the world’s most powerful supercomputers. Sorensen pointed out that training a model at this scale requires more than 10 terabytes of aggregate memory for the model weights, gradients, and optimizer states.

Bob Sorensen, Hyperion
With so much data, tokens and compute power in play, this is where the mysterious, some would say unsettling, nature of LLMs can occur, when models do certain “emergent” things even LLM specialists didn’t expect. Research is underway on how and why this happens, but until we get answers, the emergent phenomenon will tap into our fear of AI escaping the bonds of human control, as when the Hal AI machine ran riot in “2001.”
A paper published in Nature in July offered this startling observation: “Of particular interest is the ability of these models to reason about novel problems zero-shot, without any direct training (italics added). In human cognition, this capacity is closely tied to an ability to reason by analogy. Here we performed a direct comparison between human reasoners and a large language model…. We found that (OpenAI’s) GPT-3 displayed a surprisingly strong capacity for abstract pattern induction, matching or even surpassing human capabilities in most settings….”
Another paper on the arXive site states: “We consider an ability to be emergent if it is not present in smaller models but is present in larger models. Thus, emergent abilities cannot be predicted simply by extrapolating the performance of smaller models. The existence of such emergence implies that additional scaling could further expand the range of capabilities of language models.”
Are emergent LLM capabilities early tentacles reaching toward general AI? Time will tell. (For another viewpoint, see this paper, also on arXive, arguing that emergent abilities may be a mirage resulting from “the researcher’s choice of metric rather than due to fundamental changes in model behavior with scale.”)
“What’s interesting about large language models is that first ‘L,’ they’re large, very large…,” Sorensen said. “When you get to a large enough model size, things start to happen that in some sense are almost unexplainable in terms of ‘Wow, I can’t believe that we’re making these kinds of connections…’ That’s what’s really driving a lot of the LLM mindshare.”
