
The Association for Computing Machinery, named Amanda Randles of Duke University the recipient of the ACM Prize in Computing for groundbreaking contributions to computational health through innovative ….
Duke Researcher Dr. Amanda Randles Wins ACM Prize in Computing for Medical Diagnostics
April 25, 2024 by Leave a Comment
NVIDIA to Acquire Run:ai GPU Orchestration Software Vendor
April 24, 2024 by Leave a Comment

Nvidia today announced it has agreed to acquire Run:ai, a Kubernetes-based workload management and orchestration software provider. Terms were not released but TechCrunch reported the price of the acquisition was approximately $700 million, according to sources.
Lenovo Launches AI Servers with AMD MI300X GPUs
April 24, 2024 by Leave a Comment

Lenovo today announced AI-centric infrastructure systems in collaboration with AMD, including the ThinkSystem SR685a V3 8GPU server (pictured here), designed for demanding AI workloads, including genAI and large language models. The server, powered by 4th Generation AMD EPYC Genoa ….
DOD to Leverage Intel Foundry’s Advanced Process Technology
April 22, 2024 by Leave a Comment
DOD has awarded Phase Three of its Rapid Assured Microelectronics Prototypes – Commercial program to Intel Foundry. This means RAMP-C customers can manufacture prototypes on Intel 18A, the company’s most advanced process technology. Although Intel and DOD did not disclose the dollar….
Eviden Delivers 104 Pflops Nvidia-Powered EXA1-HE Supercomputer for CEA
April 17, 2024 by Leave a Comment
Paris – April 17, 2024 – CEA (The French Alternative Energies and Atomic Energy Commission) and Eviden, the Atos advanced computing business unit, today announce the delivery of the EXA1 HE supercomputer, based on Eviden’s BullSequana….
Stanford AI Index: Lax LLM Reponsibility, AI for Science Accelerates, Impact on Workers, US Leads China in Models
April 16, 2024 by Leave a Comment
The AI Index Report from Stanford’s Institute for Human-Centered AI is out, it’s an annual, thoroughgoing snapshot of the state of AI begun by the HAI in 2019. This year’s edition presents new estimates on AI training….
NTT: Photonics Network Connects Data Centers in U.S. and U.K.
April 11, 2024 by Leave a Comment
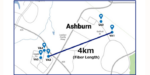
NTT Corporation (NTT) and NTT DATA announced the successful demonstration of All-Photonics Network (APN)-driven connections between data centers in the United States and the United Kingdom. In the U.K., NTT connected data centers north and east of London….
Georgia Tech Unveils AI Makerspace with NVIDIA
April 11, 2024 by Leave a Comment
Georgia Tech’s College of Engineering has established an artificial intelligence supercomputer hub dedicated exclusively to teaching students. The initiative — the AI Makerspace — was launched in collaboration with NVIDIA. College leaders call it a digital sandbox for students….
Two Researchers to Share 2024 Jack Dongarra Early Career HPC Award at ISC
April 10, 2024 by Leave a Comment

Two early career researchers, Edgar Solomonik of the University of Illinois/Urbana-Champaign and Amanda Randles of Duke University, have been selected as the recipients of the Jack Dongarra Early Career Award, to be presented at ISC 2024.
Quantinuum and Microsoft Report 800x Lower Quantum Error Rate
April 4, 2024 by Leave a Comment

Quantinuum and Microsoft report they have achieved a breakthrough in fault tolerant quantum computing “by demonstrating the most reliable logical qubits with active syndrome extraction, an achievement previously believed to be years away from realization,” the companies said.

