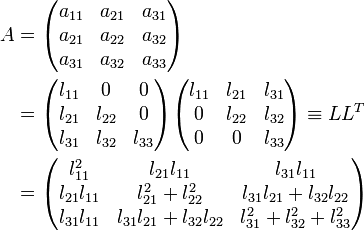
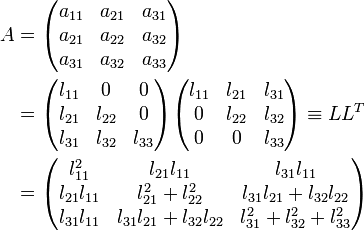 One of the most used algorithms in numerical simulation is the solving of large, dense matrices. Thermal analysis, boundary element methods and electromagnetic wave calculations all depend on the ability to solve these large matrices as fast as possible. The ability to use a coprocessor such as the Intel Xeon Phi coprocessor will greatly speed up these calculations.
One of the most used algorithms in numerical simulation is the solving of large, dense matrices. Thermal analysis, boundary element methods and electromagnetic wave calculations all depend on the ability to solve these large matrices as fast as possible. The ability to use a coprocessor such as the Intel Xeon Phi coprocessor will greatly speed up these calculations.
In order to use a coprocessor effectively, the following challenges exist:
- Massive amount of parallelism
- Coprocessors typically have less memory than main memory
- Data transfer is costly
Thus, new out of core parallel solvers are needed to take advantage of the characteristics of a hybrid architecture. The modified out of core solver was run on a small cluster which contained Intel Xeon E5-2670 processors and the Intel Xeon Phi 5110P coprocessors. Running the Cholesky factorization, the application peaked at about 370 Gflops on the Intel Xeon Phi coprocessor. Various experiments demonstrate that using a the Intel Xeon Phi coprocessor scales well for this application.
A distributed memory parallel LU and Cholesky solver can take advantage of the Intel Xeon Phi coprocessor and using out of core algorithms allows the for solving of extremely large matrices. Matrix size can be significantly greater than the available memory. Tests have shown that performance is highest in a given hybrid architecture when the ratio of data size to device memory is large.
Source: Oak Ridge National Laboratory, USA, Chinese University of Hong Kong, Hong Kong, University of Tennessee, USA
Transform data into opportunity. Speed data analysis in your applications. Intel® Parallel Studio XE

