

Peter ffoulkes, OrionX
There has been much discussion in recent years as to the continued relevance of the High Performance Linpack (HPL) benchmark as a valid measure of the performance of the world’s most capable machines, with some supercomputing sites opting out of the TOP500 completely such as National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign that houses the Cray Blue Waters machine. Blue Waters is claimed to be the fastest supercomputer on a university campus, although without an agreed benchmark it is a little hard to verify such a claim easily.
At a superficial level it appears as though any progress in the upper echelons of the TOP500 may have stalled with little significant change in the TOP10 in recent years and just two new machines added to that elite group in the November 2015 list: Trinity at 8.10 Pflop/s and Hazel Hen at 5.64 Pflop/s, both Cray systems increasing the company’s share of the TOP10 machines to 50%. The TOP500 results are available at http://www.top500.org
A new benchmark ¬- the High Performance Conjugate Gradients (HPCG) – introduced two years ago was designed to be better aligned with modern supercomputing workloads and includes system features such as high performance interconnects, memory systems, and fine grain cooperative threading. The combined pair of results provided by HPCG and HPL can act as bookends on the performance spectrum of any given system. As of July 2015 HPCG had been used to rank about 40 of the top systems on the TOP500 list.
The November TOP500 List: Important Data for Big Iron
Although being complemented by other benchmarks the HPL-based TOP500 is still the most significant resource for tracking the pace of super computing technology development historically and for the foreseeable future.
The first petascale machine, ‘Roadrunner’ debuted in June 2008, twelve years after the first terascale machine – ASCI Red in 1996. Until just a few years ago 2018 was the target for hitting the exascale capability level. As 2015 comes to its close the first exascale machine seems much more likely to debut in the first half of the next decade and probably later in that window rather than earlier. So where are we with the TOP500 this November, and what can we expect in the next few lists?

Source: TOP500.org
Highlights from the November 2015 TOP500 List on performance:
- The total combined performance of all 500 systems had grown to 420 Pflop/s, compared to 361 Pflop/s last July and 309 Pflop/s a year previously, continuing a noticeable slowdown in growth compared to the previous long-term trend.
- Just over 20% of the systems (a total of 104) use accelerator/co-processor technology, up from 90 in July 2015
- The latest list shows 80 petascale systems worldwide making a total of 16% of the TOP500, up from 50 a year earlier, and significantly more than double the number two years earlier. If this trend continues the entire TOP100 systems are likely to be petascale machines by the end of 2016.
So what do we conclude from this? Certainly that the road to exascale is significantly harder than we may have thought, not just from a technology perspective, but even more importantly from a geo-political and commercial perspective. The aggregate performance level of all of the TOP500 machines has just edged slightly over 40% of the HPL metric for an exascale machine.
Most importantly increasing the number of petascale-capable resources available to scientists, researchers, and other users up to 20% of the entire list will be a significant milestone. From a useful outcome and transformational perspective it is much more important to support advances in science, research and analysis than to ring the bell with the world’s first exascale system on the TOP500 in 2018, 2023 or 2025.
Architecture
As acknowledged by the introduction of HPCG, HPL and the TOP500 performance benchmark are only one part of the HPC performance equation.
The combination of modern multi-core 64 bit CPUs and math accelerators from Nvidia, Intel and others have addressed many of the issues related to computational performance. The focus on bottlenecks has shifted away from computational strength to data-centric and energy issues, which from a performance perspective influence HPL results but are not explicitly measured in the results. However, from an architectural perspective the TOP500 lists still provide insight into the trends in an extremely useful manner.
Source: Top500.org
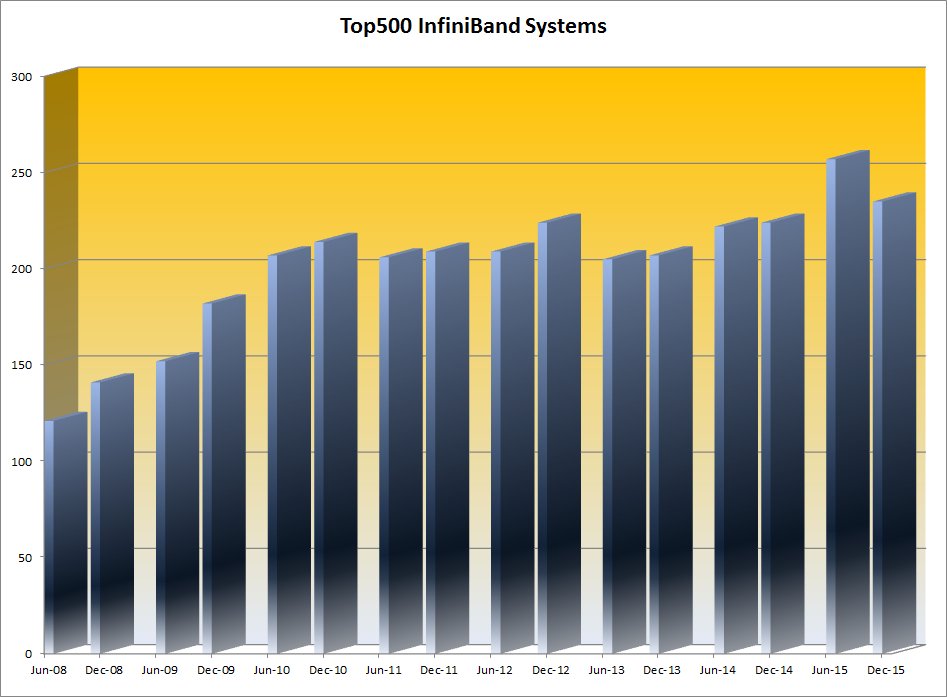
Observations from the June 2015 TOP500 List on system interconnects:
- After two years of strong growth from 2008 to 2010 InfiniBand-based TOP500 systems plateaued at 40% of the TOP500 while compute performance grew aggressively with the focus on hybrid, accelerated systems.
- The uptick in InfiniBand deployments June 2015 to over 50% of the TOP500 list for the first time does not appear to be the start of a trend, with Gigabit Ethernet systems increasing to over a third (36.4%) of the TOP500, up from 29.4%.
The TOP500: The November List and What’s Coming Soon
Although the TOP10 on the list have shown little change for a few years, especially with the planned upgrade to Tianhe 2 blocked by the US government, there are systems under development in China that are expected to challenge the 100 Pflop/s barrier in the next twelve months. From the USA, Coral initiative is expected to significantly exceed the 100 Pflop/s limit – targeting the 100 to 300 Pflop/s with two machines from IBM/Nvidia/Mellanox and one from Cray, but not before the 2017 timeframe. None of these systems are expected to deliver more than one third of exascale capability.
Vendors: A Changing of the Guard
The USA is still the largest consumer of TOP500 systems with 40% of the share by system count which clearly favors US vendors, but there are definite signs of change on the wind.
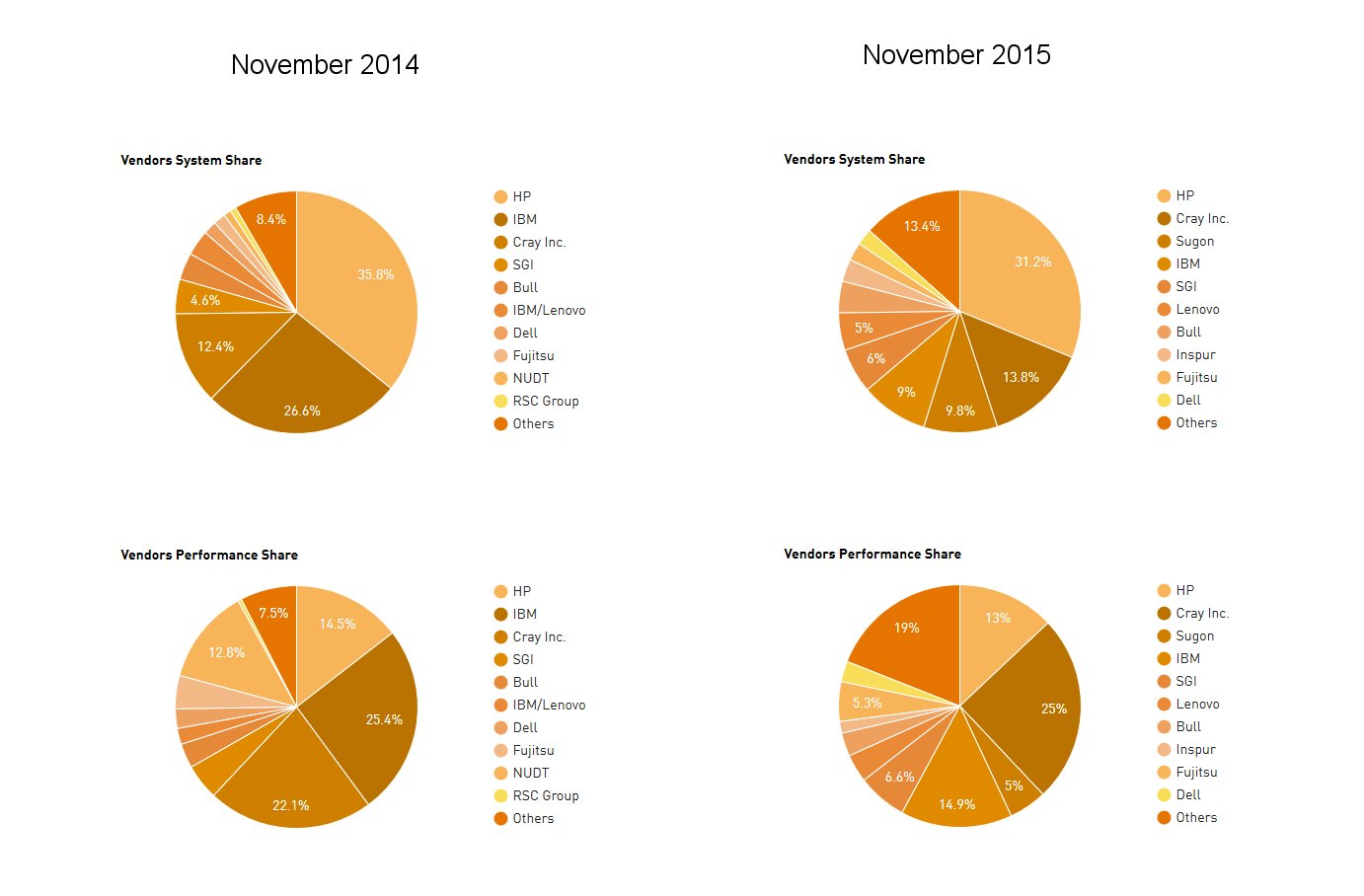
Cray is the clear leader in performance with a 24.9% share of installed total performance roughly the same as a year earlier. Each of the other leading US vendors is experiencing declining share with IBM in second place with a 14.9% share, down from 26.1% last November. Hewlett Packard is third with 12.9%, down from 14.5% a twelve months ago.
These trends are echoed in the system count numbers. HP has the lead in systems and now has 156 (31%) down from systems 179 systems (36%) twelve months ago. Cray is in second place with 69 systems (13.8%) up from 12.4% last November. IBM now has 45 systems (9%), down from 136 systems (27.2%) a year ago.
On the processor architecture front, a total of 445 systems (89%) are now using Intel processors, slightly up from 86.2 percent six months ago, with IBM Power processors now at 26 systems (5.2%), down from 38 systems (7.6%) six month ago.
Geo-Political Considerations
Perhaps the single most interesting insight to come out of the TOP500 has little to do with the benchmark itself, and the geographical distribution data which in itself underscores the importance of the TOP500 lists in tracking trends.
The number of systems in the United States has fallen to the lowest point since the TOP500 list was created in 1993, down to 201 from 231 in July. The European share has fallen to 107 systems compared to 141 on the last list and is now lower than the Asian share, which has risen to 173 systems, up from 107 the previous list and with China nearly tripling the number of systems to 109. In Europe, Germany is the clear leader with 32 systems, followed by France and the UK at 18 systems each. Although the numbers for performance-based distributions vary slightly, the percentage distribution is remarkably similar.
The USA and China divide over 60% of the TOP500 systems between them, with China having half the number and capability of the US-based machines. While there is some discussion about how efficiently the Chinese systems are utilized in comparison to the larger US-based systems, that situation is likely to be temporary and could be addressed by a change in funding models. It is abundantly clear that China is much more serious about increasing funding for HPC systems while US funding levels continue to demonstrate a lack of commitment to maintaining development beyond specific areas such as high energy physics.
 TOP500: “I Have Seen The Future and it Isn’t Exascale”
TOP500: “I Have Seen The Future and it Isn’t Exascale”
The nature of HPC architectures, workloads and markets are all in flux in the next few years, and an established metric such as the TOP500 is an invaluable tool to monitor the trends. Even though HPL is no longer the only relevant benchmark, the emergence of complementary benchmarks such as HPCG serves to enhance the value of the TOP500, not to diminish it. It will take a while to generate a body of data equivalent to the extensive resource that has been established by the TOP500.
What we can see from the current trends shown in the November 2015 TOP500 list is that although an exascale machine will be built eventually, it almost certainly will not be delivered this decade and possibly not until half way through the next decade. Looking at the current trends it is also very unlikely that the first exascale machine will be built in the USA, and much more likely that it will be built in China.
Over the next few years the TOP500 is likely to remain the best tool we have to monitor geo-political and technology trends in the HPC community. If the adage coined by the Council on Competitiveness, “To out-compute is to out-compete” has any relevance, the TOP500 will likely provide us with a good idea of when the balance of total compute capability will shift from the USA to China.


This sentence has it backwards:
From the USA, Coral initiative is expected to significantly exceed the 100 Pflop/s limit – targeting the 100 to 300 Pflop/s with two machines from Cray and one from IBM, but not before the 2017 time frame.
IBM is supplying systems to both ORNL and LLNL and Intel/Cray are supplying ANL.
Yes, you are correct, it should have been updated, but two from IBM and one at Argonne from Cray/Intel.