
When Accenture Federal Services researched how current AI technologies could be used by the U.S. federal government, Accenture documented nearly 100 use cases for AI adoption. Artificial intelligence is making a difference to government right now. For more information on how to get involved in this important and growing sector, take advantage of the resources outlined in this excerpt from an insideHPC Guide.
Augmenting & Automating Operations in Government
February 26, 2019 by

The Air Force’s top training official said it is moving toward a new “paradigm” for how it teaches airmen to fly airplanes. A new special report from insideHPC, courtesy of Dell EMC and NIVIDA, explores current machine learning applications in government. This excerpt covers recent research on the potential of AI technology in the U.S. Federal government, as well as how government AI is being used in U.S.Air Force pilot training strategies.
Finding a Solution for Ai in Government
February 19, 2019 by

A new special report from insideHPC, courtesy of Dell EMC and NIVIDa explores current machine learning applications in government. And this excerpt breaks down solutions for AI in government, including Dell EMC Ready Solutions. Dell EMC Ready Solutions for AI are validated hardware and software stacks optimized to accelerate AI initiatives, shortening the time to architect a new solution by six to 12 months.
Today’s Application of Ai Within Government
February 12, 2019 by

Across the globe, governments are acknowledging the potential of AI technologies to impact our daily lives, from how we make purchasing decisions to improving our healthcare. But there are several reasons why government agencies may be hesitant to adopt AI technologies. A new insideHPC Guide, courtesy of Dell EMC and NVIDIA, explores what’s next for government AI, as well as already tangible results of AI and machine learning.
How AI is Changing the Media & Entertainment Industry
September 17, 2018 by

This insideHPC guide series explores how artificial intelligence is revolutionizing and evolving the media and entertainment industries. To get things started, this post offers up an overview of how AI is impacting the entertainment industry and the future of these sectors.
Revolutionizing the Media and Entertainment Industry through Artificial Intelligence
September 12, 2018 by Leave a Comment

From the creative process behind the scenes, to content delivery and audience engagement, artificial intelligence is having a profound effect on the media and entertainment industry. Download the new insideHPC guide, brought to you by Dell EMC and Nvidia, to learn more about how AI is revolutionizing this sector.
Where Ready Nodes are the Optimal Choice
July 12, 2018 by
The perennial question for IT asset acquisition is whether to build or consume, and there is no ‘one size fits all’ answer to the question. Individual components provide the maximum flexibility, but also require the maximum of self support. Reference architectures provide the recipe and guidance, but the customer still has the responsibility for making the system work.
Network Switch Configuration with Dell EMC Ready Nodes
July 6, 2018 by
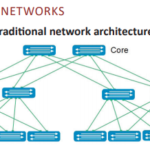
Storage networks are constantly evolving. From traditional Fibre Channel to IP-based storage networks, each technology has its place in the data center. IP-based storage solutions have two main network topologies to choose from based on the technology and administration requirements. Dedicated storage network topology, shared leaf-spine network, software defined storage, and iSCSI SAN are all supported. Hybrid network architectures are common, but add to the complexity.
Determining Where & How to Adopt Machine Learning Technology
July 3, 2018 by
The is the final entry in a five-part insideHPC series that takes an in-depth look at how machine learning, deep learning and AI are being used in the energy industry. Read on for help determining where and how to adopt machine learning technology in your business.
Networking Dell EMC Microsoft Storage Spaces Direct Ready Nodes
June 27, 2018 by
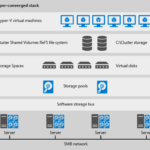
Dell EMC Microsoft Storage Spaces Direct Ready Nodes are built on Dell EMC PowerEdge servers, which provide the storage density and compute power to maximize the benefits of Storage Spaces Direct. “They leverage the advanced feature sets in Windows Server 2016 Datacenter Edition to deploy a scalable hyper-converged infrastructure solution with Hyper-V and Storage Spaces Direct. And for Microsoft server environments, S2D scales to 16 nodes in a cluster, and is a kernel-loadable module, (with no RDMA iWarp or RoCE needed) which is a low risk approach to implementing an S2D cluster.”

