
 In this video from SC16, John McCalpin presents: Memory Bandwidth and System Balance in HPC Systems.
In this video from SC16, John McCalpin presents: Memory Bandwidth and System Balance in HPC Systems.
“The ‘Attack of the Killer Micros’ began approximately 25 years ago as microprocessor-based systems began to compete with supercomputers (in some application areas). It became clear that peak arithmetic rate was not an adequate measure of system performance for many applications, so in 1991 Dr. McCalpin introduced the STREAM Benchmark to estimate “sustained memory bandwidth” as an alternative performance metric. STREAM apparently embodied a good compromise between generality and ease of use and quickly became the “de facto” standard for measuring and reporting sustained memory bandwidth in High Performance Computing systems. Since the initial “attack”, Moore’s Law and Dennard Scaling have led to astounding increases in the computational capabilities of microprocessors. The technology behind memory subsystems has not experienced comparable performance improvements, causing sustained memory bandwidth to fall behind.
This talk reviews the history of the changing balances between computation, memory latency, and memory bandwidth in deployed HPC systems, then discusses how the underlying technology changes led to these market shifts. Key metrics are the exponentially increasing relative performance cost of memory accesses and the massive increases in concurrency that are required to obtain increased memory throughput. New technologies (such as stacked DRAM) allow more pin bandwidth per package, but do not address the architectural issues that make high memory bandwidth expensive to support. Potential disruptive technologies include near-memory-processing and application-specific system implementations, but all foreseeable approaches fail to provide software compatibility with current architectures. Due to the absence of practical alternatives, in the near term we can expect systems to become increasingly complex and unbalanced, with constant or slightly increasing per-node prices. These systems will deliver the best rate of performance improvement for workloads with increasingly high compute intensity and increasing available concurrency.”
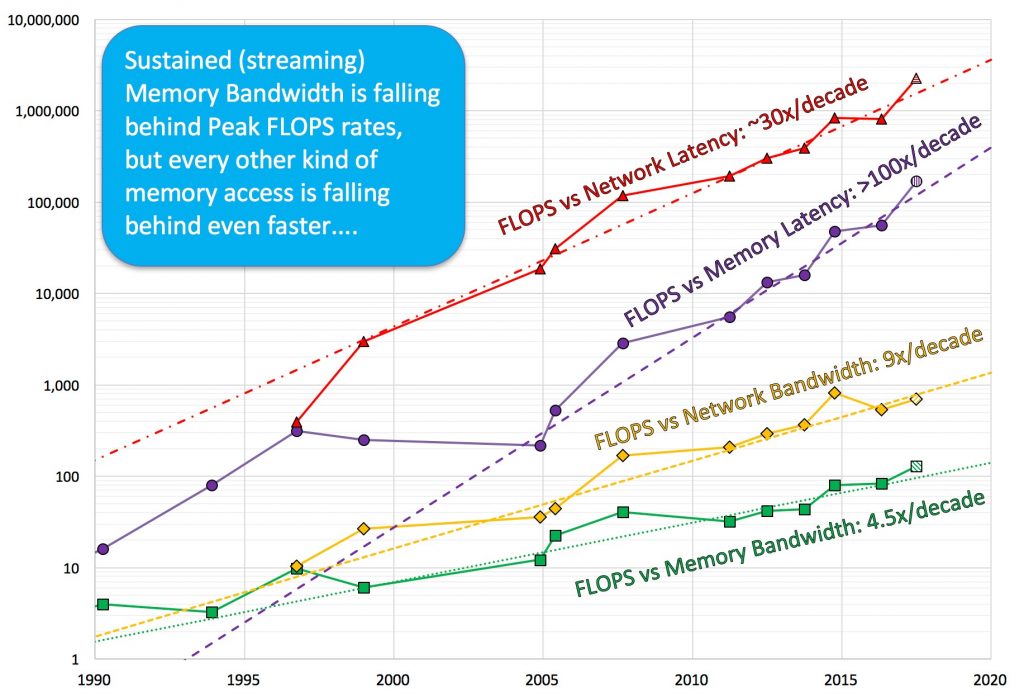
Trends in the relative performance of floating-point arithmetic and several classes of data access for select HPC servers over the past 25 years.
Dr. John D. McCalpin is a Research Scientist in the High Performance Computing Group and Co-Director of ACElab at TACC of the University of Texas at Austin. At TACC, he works on performance analysis and performance modeling in support of both current users and future system acquisitions.

