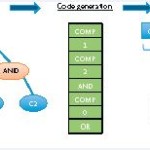
As datasets and simulations continue to increase in size and complexity, interactivity with the data should be maintained. It is important to understand how SIMD parallelism can be used when evaluating large fault tree expressions on a large volume of input.
At the Convergence of HPC, AI and Quantum

