

Natalia Ruiz Juri of the Center for Transportation Research, The University of Texas at Austin
Over at TACC, Faith Singer-Villalobos writes that researchers are using the Rustler supercomputer to tackle Big Data from self-driving connected vehicles (CVs).
“The volume and complexity of CV data are tremendous and present a big data challenge for the transportation research community,” said Natalia Ruiz-Juri, a research associate with The University of Texas at Austin’s Center for Transportation Research. While there is uncertainty in the characteristics of the data that will eventually be available, the ability to efficiently explore existing datasets is paramount.
Ruiz-Juri and her colleagues, including Chandra Bhat, James Kuhr and Jackson Archer, were interested in exploring the most comprehensive data set released to date — the Safety Pilot Model Deployment (SPMD) data, produced by a study conducted by The University of Michigan Transportation Research Institute and the National Highway Traffic Safety Administration.
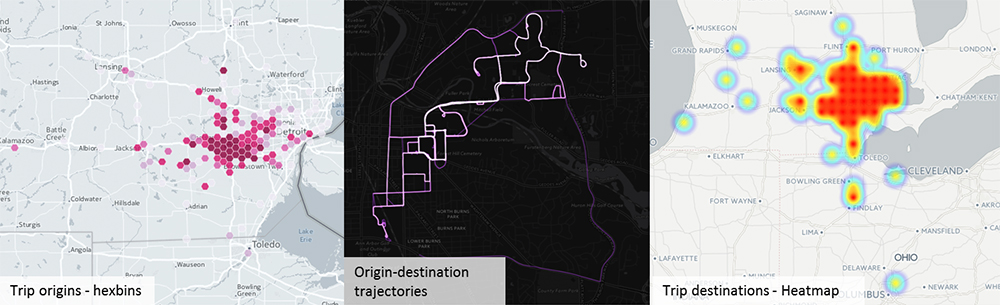
Preliminary visualization of trip-level data after processing on Rustler.
However, to get started they needed help using computational resources. They turned to the Texas Advanced Computing Center (TACC), also at UT Austin, and a key partner in the Extreme Science and Engineering Discovery Environment (XSEDE), the most advanced, powerful, and robust collection of integrated advanced digital resources and services in the world. Through XSEDE, Ruiz-Juri and team took advantage of the Extended Collaborative Support Services (ECSS) program, and the TACC experts within the program, to make these resources easier to use and to help more people use them.
TACC ECSS experts Weijia Xu and Amit Gupta were able to help Ruiz-Juri and her colleagues figure out how to use very large datasets on supercomputers like Rustler, TACC’s experimental system for exploring new storage and data compute techniques and technologies.
Ruiz-Juri and her colleagues compared efforts to build scalable solutions for CV data analysis using Hive, an open-source data warehouse application that supports distributed queries. The data included approximately 2,700 cars, trucks and transit buses whose activities were logged through on-board sensors over a two month period.

Rustler Supercomputer at TACC
“Hive is an ideal choice in this particular use case since it not only offers scalability and performance but also has a SQL-like interface,” Xu said, referring to Structured Query Language used to manage data. “It is similar to PostgreSQL which the research team is already familiar with.”
According to Ruiz-Juri, using Rustler is a huge time-saver because it lets them play with the data and see what it looks like without spending hours waiting for a query to complete.
As a researcher, Ruiz-Juri said one of the challenges she faces is not knowing which system to use on a particular model for a particular dataset. This is one of the many ways that Xu and Gupta were able to help. They developed an automated methodology to understand how each system is expected to perform based on the characteristics of the network. For this work they used Rustler, but soon they plan to move the data to Wrangler, an XSEDE-allocated resource.
Natalia and her colleagues were trying to make sense of the data,” Gupta said. “It’s unfiltered data from real people capturing their movement patterns across the city. All of this data was sampled at 10 times per second — speed data, when a person used their brakes, when they used their windshield wipers etc — so it’s a lot of information and nobody has completely figured out what to do with it. Natalia and her team are trying to validate, and in some cases possibly break through, some of the assumptions that they traditionally made in their field with respect to traffic patterns.”
The goal is to enable their research exploration by leveraging HPC tools and infrastructure, according to Gupta. Due to the scale of such resources available at TACC, they are able to iterate through their analysis cycle much quicker and converge towards conclusions faster. It also enables them to attempt new simulation experiments that would overload their computational resources or take prohibitively long to run.

