@HPCpodcast Industry View: A Portrait of LRZ’s Upcoming HPE Cray Supercomputer Powered by NVIDIA Vera Rubin – the Combined Forces of HPC and AI for Science
@HPCpodcast’s “Industry View” episodes take on major issues in advanced technologies through the lens of industry leaders. In this episode, we dig into the design and deployment of an upcoming leadership-class supercomputer for the Leibniz Supercomputing Centre (LRZ) in Germany. This is the “Blue Lion” HPC system ….
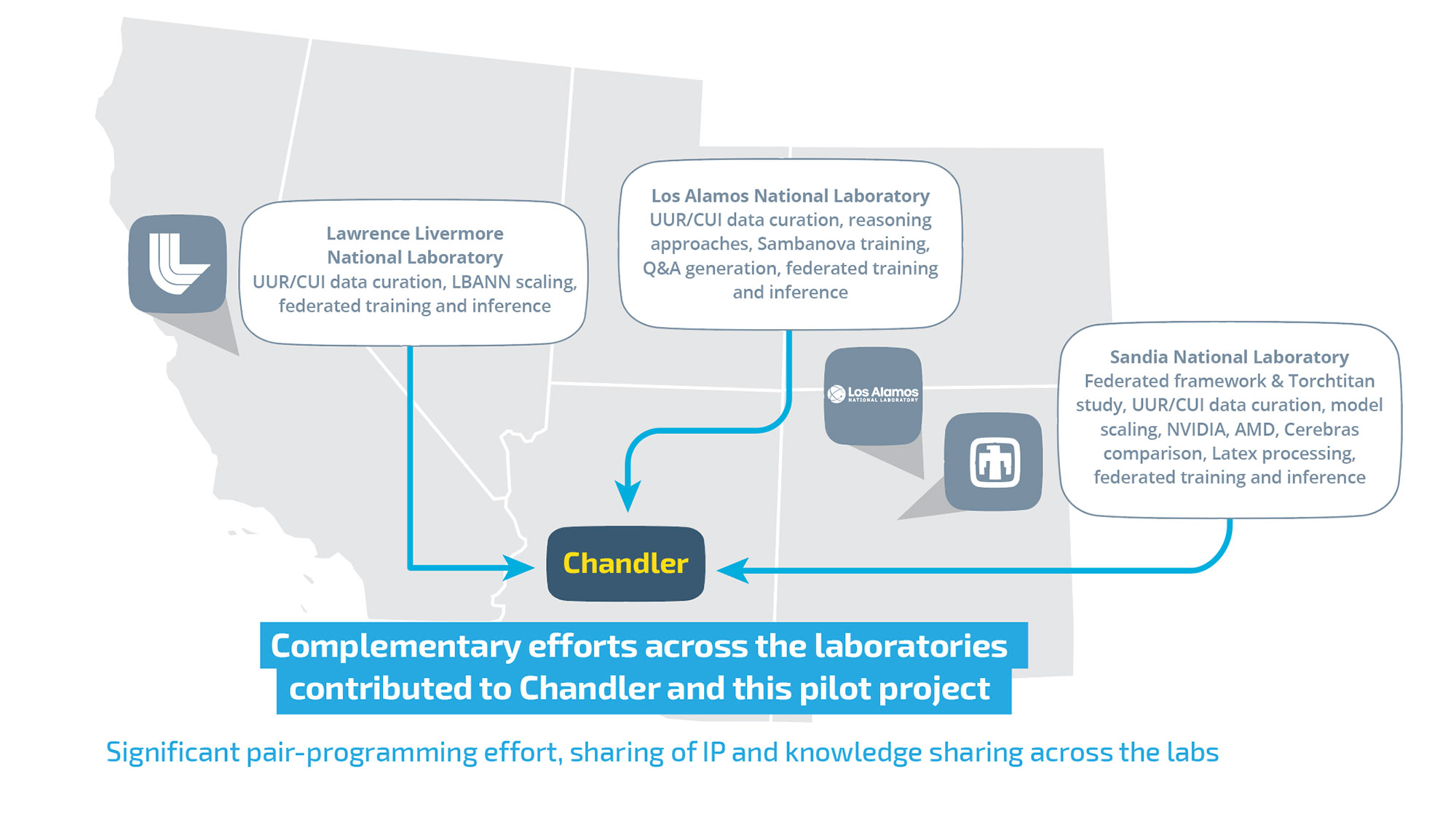
3 National Security Labs, 1 Federated Learning AI Model
Sandia National Laboratories released information today spotlighting what the labs call a significant milestone in advancing artificial intelligence for national security. Over the past year, Sandia, Los Alamos and Lawrence Livermore national laboratories ….

EuroHPC JU Issues €4M HPC-AI Benchmarking Call for Proposals, March 24 Deadline
The European High-Performance Computing Joint Undertaking has launched a call for benchmarking proposals for HPC systems in Europe. This call for proposals, HORIZON-EUROHPC-JU-2024-BENCHMARK-05 ….
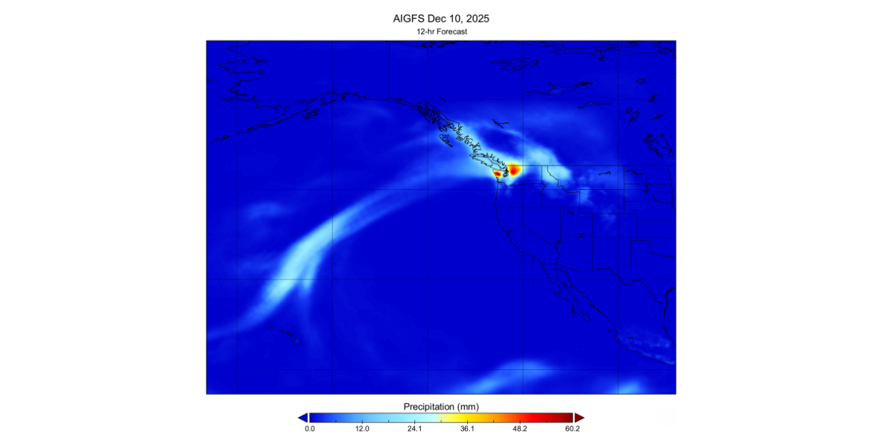
NOAA Deploys AI-Driven Global Weather Models
The U.S. National Oceanic and Atmospheric Administration said it has launched a suite of operational, artificial intelligence-driven global weather prediction models that NOAA said marks an advancement in forecast speed, efficiency, and accuracy ….
Sponsored Guest Article

Why Is Drivenet’s Fabric Scheduled Ethernet the Best InfiniBand Alternative?
[SPONSORED GUEST CONTENT] Scheduled Ethernet is emerging as a viable alternative to InfiniBand for AI networking. Why? Because of its ability to offer comparable performance but with greater flexibility and cost-effectiveness.
@HPCpodcasts
-
@HPCpodcast Industry View: A Portrait of LRZ’s Upcoming HPE Cray Supercomputer Powered by NVIDIA Vera Rubin – the Combined Forces of HPC and AI for Science
@HPCpodcast’s “Industry View” episodes take on major issues in advanced technologies through the lens of industry leaders. In this episode, we dig into the design and deployment of an upcoming leadership-class supercomputer for the Leibniz Supercomputing Centre (LRZ) in Germany. This is the “Blue Lion” HPC system ….

HPC News Bytes 20251215: On-Off-On GPU Exports to China, the US-China Power Gap, Pocket-Sized HPC, Regulating AI
Warmest December greetings! AI technology and its impacts splashed around the world last week, here’s a fast (10:52) review of new developments, including: Nvidia H200 exports to China ….
HPC News Bytes 20251208: Marvell’s Celestial AI-Optical I/O Buy, ASML’s U.S. EUV Laser Competitor, HPC and Parkinson’s Research at SDSC
A good December day to you! The world of HPC-AI generated a notably colorful array of developments last week, here’s a quick (9:12) run-through of recent news: Marvell in AI with Celestial AI ….
White Papers

The Journey to Exascale
High-performance computing (HPC) has fundamentally changed the world of scientific research. Complex challenges that previously were unapproachable due to compute performance limitations and the massive power demands of legacy platforms can now be effectively addressed via powerful new advances in HPC. The U.S. Department of Energy (DOE) is at the forefront of HPC, pushing its […]

A Beginner’s Guide to Large Language Models
The goal of this book is to help enterprises understand what makes LLMs so groundbreaking compared to previous solutions and how they can benefit from adopting or developing them. It also aims to help enterprises get a head start by outlining the most crucial steps to LLM development, training, and deployment. To achieve these goals, […]

Mastering the Complexities of AI at Scale
Artificial intelligence (AI), one of the most transformative innovations in enterprise IT, will continue to dominate the technology landscape for the foreseeable future. Organizations across industries are leveraging AI to differentiate their offerings and secure their competitive advantage. However, maximizing AI’s potential requires AI-optimized hardware and software as well as the specialized knowledge needed to […]
ISC 2025 Videos
At ISC 2024: Intel’s Open Software Strategy for HPC and AI







Editor’s Choice

$200M HPC Data Center for AI in Wisconsin Launched by DPO and Billerud
Digital Power Optimization, Inc. (“DPO”), a developer and operator of power-dense data centers, today announced it has secured land and a power supply to develop a $200 million high-performance computing facility in Wisconsin Rapids, WI. This project will enable up to 20 megawatts of AI computing. DPO is working in partnership with Billerud subsidiary Consolidated Water Power Company ….

@HPCpodcast Industry View: A Deep Dive into High-Density Data Center Cooling and Efficiency Strategies with DDC Solutions
In this “Industry View” episode of the @HPCpodcast, Chris Orlando of DDC Solutions discusses the rapidly changing landscape of high density data center cooling, monitoring, safety and compliance, hybrid liquid-air solutions and other strategies for data center power efficiency. DDC’s cabinet technology, DCIM real-time monitoring and dynamic ….

@HPCpodcast Industry View: A Deep Dive into High-Density Data Center Cooling and Efficiency with DDC Solutions
Chris Orlando of DDC discusses the rapidly changing landscape of high density data center cooling, monitoring, safety ….
Sponsored Guest Articles

Webinar: How to Prepare for Quantum, with Insights from Alice & Bob and Hyperion Research
The state of quantum is full of promise and in a constant flux, so much so that it’s hard to keep track of. In this webinar, we have Julliette Peyronnet of French ….

How MiTAC Helps Organizations Scale for Both AI Training and Inference
“Our design philosophy is centered around our customers. They need solutions that are not just technically advanced but also seamlessly integrated, easily scalable, and reliable.”

Unleashing Power: NVIDIA L40S Data Center GPU by PNY
The NVIDIA L40S Data Center GPU, provided by PNY, represents a significant leap forward in the realm of high-performance computing. This GPU is engineered to meet the demanding needs of modern data centers ….