This feature continues our series of articles that survey the landscape of HPC and AI. This final post explores AI hardware options to support the growing artificial intelligence software ecosystem.

Balance ratios are key to understanding the plethora of AI hardware solutions that are being developed or are soon to become available. Future proofing procurements to support run-anywhere solutions—rather than hardware specific solutions—is key!
The basic idea behind balance ratios is to keep what works and improve on those hardware characteristics when possible. Current hardware solutions tend to be memory bandwidth bound. Thus, the flop/s per memory bandwidth balance ratio is critical for training. So long as there is sufficient arithmetic capability to support the memory (and cache bandwidth), the hardware will deliver the best average sustained performance possible. Similarly, the flop/s per network performance is critical for scaling data preprocessing and training runs. Storage IOP/s (IO Operations per Second) is critical for performing irregular accesses in storage when working with unstructured data.
Compute
The future of AI hardware includes CPUs, accelerators/ purpose-built hardware, FPGAs and future neuromorphic chips. For example, Intel’s CEO Brian Krzanich said the company is fully committed to making its silicon the “platform of choice” for AI developers. Thus, Intel efforts include:
- CPUs: including the Intel Xeon Scalable processor family for evolving AI workloads, as well as Intel Xeon Phi processors.
- Special purpose-built silicon for AI training such as the Intel Neural Network Processor family.
- Intel FPGAs, which can serve as programmable accelerators for inference.
- Neuromorphic chips such as Loihi neuromorphic chips.
- Intel 17-Qubit Superconducting Chip, Intel’s next step in quantum computing.
[clickToTweet tweet=”The future of AI includes CPUs, accelerators/ purpose-built hardware, FPGAs and future neuromorphic chips. #HPC” quote=”The future of AI includes CPUs, accelerators/ purpose-built hardware, FPGAs and future neuromorphic chips. #HPC”]
Although a nascent technology, it is worth noting it because machine learning can potentially be mapped to quantum computers. If this comes to fruition, such a hybrid system could revolutionize the field.
CPUs such as Intel Xeon Scalable processors and Intel Xeon Phi
The new Intel Xeon Scalable processors deliver a 1.65x on average performance increase for a range of HPC workloads over previous Intel Xeon processors due to a host of microarchitecture improvements that include: support for Intel Advanced Vector Extensions-512 (Intel AVX-512) wide vector instructions, up to 28 cores or 56 threads per socket, support for up to eight socket systems, an additional two memory channels, support for DDR4 2666 MHz memory, and more.
[clickToTweet tweet=”The Intel Xeon Phi product family presses the limits of CPU-based power efficiency. #HPC” quote=”The Intel Xeon Phi product family presses the limits of CPU-based power efficiency. #HPC”]
The Intel Xeon Phi product family presses the limits of CPU-based power efficiency coupled with many-core parallelism: two per-core Intel AVX-512 vector units that can make full use of the high-bandwidth HMB2 stacked memory. The 15 PF/s distributed deep learning result utilized the Intel Xeon Phi processor nodes on the NERSC Cori supercomputer.
Intel Neural Network Processor
Intel acquired AI hardware Nervana Systems in August 2016. As previously discussed, Intel Nervana Graph will act as a hardware agnostic software intermediate language that can provide hardware specific optimized performance.
On October 17, 2017, Intel announced it will ship the industry’s first silicon for neural network processing, the Intel Nervana Neural Network Processor (NNP), before the end of this year. Intel’s CEO Brian Krzanich stated at the WSJDlive global technology conference, “We have multiple generations of Intel Nervana NNP products in the pipeline that will deliver higher performance and enable new levels of scalability for AI models. This puts us on track to exceed the goal we set last year of achieving 100 times greater AI performance by 2020.”
Intel’s R&D investments include AI hardware, data algorithms and analytics, acquisitions, and technology advancements. At this time, Intel has invested $1 Billion in the AI ecosystem.
Intel’s broad investments in AI
The Intel Neural Network Processor is an ASIC featuring 32 GB of HBM2 memory and 8 Terabits per Second Memory Access Speeds. A new architecture will be used to increase the parallelism of the arithmetic operations by an order of magnitude. Thus, the arithmetic capability will balance the performance capability of the stacked memory.
The Intel Neural Network Processor will also be scalable as it will feature 12 bidirectional high-bandwidth links and seamless data transfers. These proprietary inter-chip links will provide bandwidth up to 20 times faster than PCI Express links.
FPGAs
FPGAs are natural candidates for high speed, low-latency inference operations. Unlike CPUs or GPUs, FPGAs can be programmed to implement just the logic required to perform the inferencing operation and with the minimum necessary arithmetic precision. This is referred to as a persistent neural network.
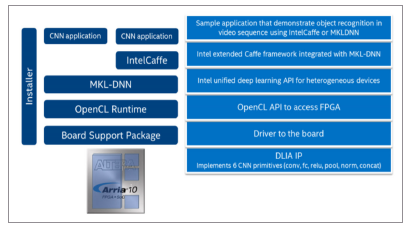
From Intel Caffe to FPGA35 (source Intel)
Intel provides a direct path from a machine learning package like Intel Caffe through Intel MKL-DNN to simplify specification of the inference neural network. For large scale, low-latency FPGA deployments, see Microsoft Azure.
Neuromorphic Chips
As part of an effort within Intel Labs, Intel has developed a self-learning neuromorphic chip—codenamed Loihi—that draws inspiration from how neurons in biological brains learn to operate based on various modes of feedback from the environment. The self-learning chips uses asynchronous spiking instead of the activation functions used in current machine and deep learning neural networks.

A Loihi
neuromorphic chip
manufactured by Intel.
Loihi has digital circuits mimicking the basic mechanics of the brain, corporate vice president and managing director of Intel Labs Dr. Michael Mayberry said in a blog post, which requires lower compute power while making machine learning more efficient. These chips can help “computers to self-organize and make decisions based on patterns and associations,” Mayberry explained. Thus, neuromorphic chips hold the potential to leapfrog current technologies.
Network: Intel Omni-Path Architecture (Intel OPA)
Intel Omni-Path Architecture (Intel OPA), a building block of Intel Scalable System Framework (Intel SSF), is designed to meet the performance, scalability, and cost models required for both HPC and deep learning systems. Intel OPA delivers high bandwidth, high message rates, low latency, and high reliability for fast communication across multiple nodes efficiently, reducing time to train.
Intel Scalable
Systems Framework
To reduce cluster-related costs, Intel has launched a series of Intel Xeon Platinum and Intel Xeon Gold processor SKUs with Intel OPA integrated onto the processor package to provide access to this fast, low-latency 100Gbps fabric. Further, the on-package fabric interface sits on a dedicated internal PCI Express bus, which should provide more IO flexibility. AI applications tend to be network latency limited due to the many small messages that are communicated during the reduction operation.
Storage
Just as with main memory, storage performance is dictated by throughput and latency. Solid State storage (coupled with distributed file systems such as Lustre) is one of the biggest developments in unstructured data analysis.
Instead of being able to perform a few hundred IOP/s, an SSD device can perform over half a million random IO operations per second. This makes managing big data feasible as discussed in ‘Run Anywhere’ Enterprise Analytics and HPC Converge at TACC where researchers are literally working with an exabyte of unstructured data on the TACC Wrangler data intensive supercomputer. Wrangler provides a large-scale storage tier for analytics that delivers a bandwidth of 1TB/s and 250M IOP/s.
The insideHPC Special Report on AI-HPC also covered the following topics:
- An Overview of AI in the HPC Landscape
- AI and HPC: Inferencing, Platforms & Infrastructure
- AI Technology: The Answer to Diffusion Compartment Imaging Challenges
- AI Systems Designed to Learn in a Limited Information Environment
- AI Software: Understanding the Rapidly Expanding Ecosystem
Download the full report: “insideHPC Special Report: AI-HPC is Happening Now” courtesy of Intel.
