 Introduction
Introduction
Deciding on the correct type of GPU accelerated computation hardware depends on many factors. One particularly important aspect is the data flow patterns across the PCIe bus and between GPUs and Intel® Xeon® Scalable processors. These factors, along with some application insights are explored below.
Data Flow Options for Fast Computation
Moving data quickly has always been a key feature of HPC performance. All data transfers from a storage device (spinning disk or solid-state) to memory, to the CPU and back again. With traditional CPU based computing, this movement is often well optimized. The introduction of GPU acceleration introduced different possible data paths and, thus, other avenues for optimization.
In today’s systems, the PCIe bus is used to connect peripheral devices to the CPU and memory. In particular, when PCIe based GPU accelerators are added to Intel® Xeon® systems, data moves between the main memory and GPU over the PCIe bus. This approach works well for single CPUs and GPUs, however, in modern multi-processor (each with multiple cores) and multi-GPU systems, there are multiple options to consider when moving data between disk, memory, CPU, and GPU components.
For example, when using a GPU to accelerate computing, data has historically been transferred from disk to local CPU memory and then to the GPU memory. This process can be optimized using GPUDirect peer-to-peer communication where data can be moved directly over the PCIe bus from one GPU to another without involving the local CPU or memory. In addition, GPUDirect can directly access network and storage devices. Currently, the top transfer speed over the PCIe bus can range between 16-32 GB/sec.
Another new technology, NVLink, is designed for GPUs is a direct GPU-to-GPU connection protocol that allows GPUs to communicate directly (i.e. they do not use the PCIe bus) over a specialized link at peak data rates of 300 GB/s. The NVLink technology can directly connect up to eight GPUs without a switch and sixteen with a switch. In essence, a GPU-to-GPU link allows multiple GPUs to operate as a single GPU from the programmers perspective. This feature is desirable to Deep Learning applications.
Single-Root vs Dual-Root Systems
When considering what type of GPU/CPU data flow, the PCIe bus design is of utmost importance. Leading server vendors offer two basic designs; a single-root and a dual-root configuration. HPC servers typically have two processors (sockets) and separate memory zones assigned to each processor. To share the memory between processors, Intel platforms have high speed interprocessor links called Ultra Path Interconnect (UPI) or Intel QuickPath Interconnect (QPI).
A “dual-root” configuration is created in some designs where the PCIe bus is split across the processors. This design places approximately half of the PCIe “slots” on each processor. Access to the “other PCIe” slots takes place over the interprocessor links. A second design uses a “single-root” approach where all PCIe “slots” are connected using a PCIe switch to a single processor. The single-root unified PCIe bus does not require the inter-processor links, and all PCIe access (and device speeds) are consistent, but connected to one processor. The second processor if free to assist with all CPU based computation.
Both of these methods may have advantages and disadvantages depending on the application data flow. A dual-root design allows for simultaneous transactions on both buses. For example, the GPUs could be split evenly across the PCIe buses allowing simultaneous transfers. This configuration can be advantageous for computational applications where data flow between CPU-memory and GPU-memory can be a rate-limiting step in the computation.
In a similar vein, a server may have multiple GPUs on one PCIe bus and a high speed network connection (e.g. InfiniBand or possibly a storage device) on the other. Data flow from CPU-memory to GPU-memory can happen simultaneously while data are moving to and from the server via the network interface (or storage device). GPU accelerated HPC applications that require large amounts of MPI traffic may find this design beneficial.
By contrast, the single-root design exposes all the PCIe slots to one of the processors. This approach can be advantageous for many Deep Learning systems because it allows fast memory movement from one GPU to another using a GPUDirect transfer over the PCIe bus (i.e., the data transfer does not involve the CPU and does not have to travel across any UPI or QPI processor links). If a direct GPU-to-GPU link is used, once loaded, data in the GPU-memories never leaves the GPU complex and can be shared by all the GPUs.
Choosing an Optimal Hardware Design For Your Application
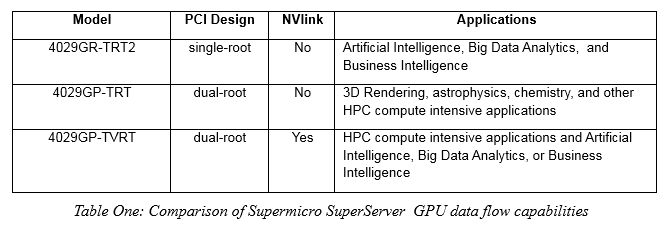
To help understand the system choices, consider three Supermicro 4U systems, SuperServer 4029GR-TRT, SuperServer 4029GR-TRT2 and the SuperServer 4029GP-TVRT. Each system provides Dual Socket 2nd Gen Intel® Xeon® Scalable processors (Cascade Lake/Skylake), with up to 6TB ECC memory (with support for Intel® Optane™), up to 24 hot-swap 2.5″ drive bays, 2x 10GBase-T LAN, redundant power supplies and support for GPUs. The main difference between these powerful machines is the GPU data flow design.
The SuperServer 4029GR-TRT2 supports up to ten PCI-E GPU accelerators with a single-root PCI-E design that improves GPU peer-to-peer communication performance. The single-root design provides better performance for Artificial Intelligence, Big Data Analytics, and Business Intelligence, where GPUDirect is used extensively. The TRT2 does not support NVLink, however.
Conversely, the SuperServer 4029GP-TRT or the 4029GP-TVRT both support up to eight GPUs with a dual-root PCIe design that provides excellent CPU-memory to GPU-memory performance pathways. The 4029GP-TRT does not support NVLink and works best with 3D Rendering, astrophysics, chemistry, cloud and virtualization, and other HPC compute-intensive applications. In addition, the 4029GP-TVRT performs impressively in these areas and also provides an excellent fast platform for Artificial Intelligence, Big Data Analytics, or Business Intelligence applications due to the inclusion of an NVLink option for the GPUs.
Depending on your hardware performance needs, there are many other options offered by Supermicro.
Conclusion
The choice of data flow design is an essential aspect in determining optimal performance and can depend on the type of applications running on the system. When using GPUs and Intel® Xeon® processors, these general rules may apply to your application;
- For HPC applications, consider dual-root PCIe bus design that optimizes CPU-memory to GPU-memory transfers.
- For Deep Learning applications consider a single-root PCIe design that optimizes GPU-to-GPU transfers using a direct copy or a dual root design that supports the faster GPU-to-GPU NVLink.
In either case, Supermicro provides a hardware platform to ensure your GPU accelerated server data flow is matched to your application needs.
Learn more at at https://www.supermicro.com/en/products/GPU
