SAN JOSE, Feb 20, 2024 – Samsung Electronics Co., Ltd. today announced a collaboration to deliver Arm Cortex-X CPU developed on Samsung Foundry’s Gate-All-Around (GAA) process technology. This initiative is built on a partnership with devices shipped with Arm CPU intellectual property on various process nodes offered by Samsung Foundry. This collaboration will lead to […]
HPC News Bytes 20231023: Flared Gas GPU Cloud, IBM AI Chip, TSMC Q3 Earnings, Aurora Install; AI and More AI
October 23, 2023 by

Our fleet-footed (5:20) run through recent HPC news looks at: HPE Cray supercomputers to be used at flared gas generative AI data centers; IBM announces NorthPole AI chip prototype, TSMC’s down Q3 earnings; new trends in advanced AI, including detection of brain waves as an AI input; an Aurora installation update….
HPC, AI, ML and Edge Solutions Drive Duos Railcar Inspection System Powered by Dell Technologies and Kalray
October 2, 2023 by
Industries such as railways are moving from traditional inspection methods to using AI and ML to perform automated inspection of….
HPC News Bytes 20230905: Google Cloud Teams with NVIDIA; Arm Neoverse; ETH’s Hoefler Also at CSCS; RHEL
September 5, 2023 by

A hearty and happy September to you. This week’s HPC News Bytes hops across the (5:00) key developments in HPC-AI. We look at: Google Cloud Platform’s “AI-optimized infrastructure” with TPU v5e and Nvidia H100’s; Arm Neoverse Compute Subsystem; ETH’s Torsten Hoefler now also CSCS Chief Architect for ML; @HPCpodcast: Greg Kurtzer on the RHEL source code controversy.
Arm Introduces Neoverse Compute Subsystems
August 28, 2023 by
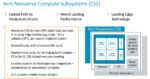
At Hot Chips today, Arm introduced the Arm Neoverse Compute Subsystems (CSS) designed to enable Arm users to build specialized silicon at lower cost, with less risk and faster time-to-market compared to discrete IP. Available today, Arm CSS N2 is a pre-integrated, PPA-optimized configuration of the Neoverse N2….
AMD Introduces FPGA-Based Adaptive SoC for Semiconductor Emulation and Prototyping
June 27, 2023 by
AMD today announced the AMD Versal Premium VP1902 adaptive system-on-chip (SoC), which the company said is the largest1 adaptive SoC. The processor is an emulation-class, chiplet-based device for streamlining the verification of semiconductor designs. Offering 2X2 the capacity over the prior generation, AMD said designers can innovate and validate application-specific integrated circuits (ASICs) and SoC designs […]
Multicore Processor Design Pioneer Prof. Kunle Olukotun Receives ACM-IEEE CS Eckert-Mauchly Award
June 7, 2023 by

New York, June 7, 2023 – ACM, the Association for Computing Machinery, today announced that Kunle Olukotun, a professor at Stanford University, is the recipient of the ACM-IEEE CS Eckert-Mauchly Award for contributions and leadership in the development of parallel systems, especially multicore and multithreaded processors. In the early 1990s, Olukotun became a leading designer of a new kind […]
UK Startup VyperCore Says Its RISC-V Chip’s Memory Management Innovation Delivers 10X Performance Boost
May 4, 2023 by
A UK chip startup, VyperCore, says it has come up with a memory management scheme that does a software layer end-around and delivers as much as a 10x throughput improvement for high performance, general-purpose workloads without code modification. The company’s core insight, as described in a recent EE Times article: move “away from the processor’s […]
Purdue Announces GPU Expansion of Gilbreth HPC Cluster
April 28, 2023 by
April 27, 2023, West Lafayette, IN — The Rosen Center for Advanced Computing (RCAC) at Purdue University has added 104 new NVIDIA A100 GPUs to the Gilbreth community HPC cluster. Based on Dell PowerEdge R7525 compute nodes with .5 TB of RAM, two Nvidia A100 Tensor Core GPUs, and 100 Gbps HDR Infiniband, this expansion […]
TSMC Reports Progress on 2nm Technology and 3nm Process at 2023 Technology Symposium
April 28, 2023 by
SANTA CLARA, CA, Apr. 26, 2023 – TSMC (TWSE: 2330, NYSE: TSM) showcased its latest technology developments at its 2023 North America Technology Symposium, including progress in 2nm technology and new members of its 3nm technology family. These include N3P, an enhanced 3nm process for better power, performance and density, N3X, a process tailored for […]

