
By Braden Cooper, Product Marketing Manager at One Stop Systems
Today’s technology shift towards AI model training and AI inferencing on massive data sets has created a unique challenge for advanced HPC designs. While the data compounds with advances in sensor and networking technology, the need to process the data at the same rate or faster grows. In the data science community, the time it takes to train a model on a new dataset can have a snowball effect on the usefulness, profitability, or implementation timeline of the end application. For AI inferencing platforms, the data must be processed in real time to make the split-second decisions that are required to maximize effectiveness. Without compromising the size of the data set, the best way to scale the model training speed is to add modular data processing nodes.
In the world of AI, the path to more compute power is more GPUs within a compute fabric. Each GPU that can be added to an AI training platform increases the parallel compute capability of the overall system. However, many AI compute platforms are limited in critical aspects such as available power, cooling, expansion slots, and rack space. In these scenarios, data scientists look to use PCIe expansion systems designed to meet the scalability needs of their datasets. PCIe expansion systems offer a modular and scalable way of adding GPUs to a compute fabric in a dense, controlled, and reliable form factor.
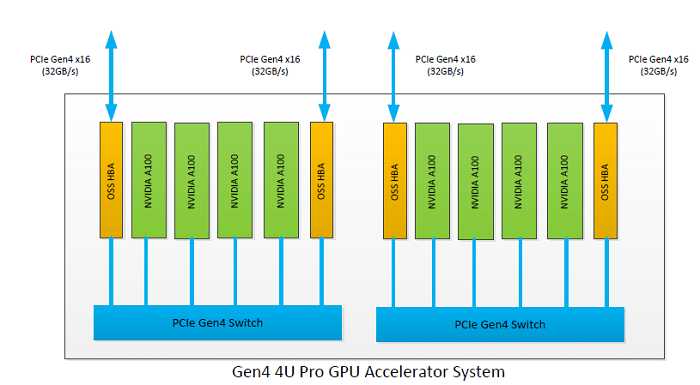
 The OSS 4U Pro GPU Accelerator System connects to one or multiple host nodes to add 8 PCIe Gen4 x16 expansion slots for the latest NVIDIA A100 Tensor Core GPUs. The A100 GPUs can be used individually or linked physically using an NVIDIA® NVLink™ Bridge to take advantage of NVLink 600 GB/s interconnect throughput. The 4U Pro system uses up to four PCIe Gen4 x16 Host Bus Adapters to bring the data into and out of the compute accelerator at speeds up to 128 GB/s. 4U Pro advanced features including redundant AC or DC inlet power, IPMI system monitoring, dynamic fan speed control. Configurable host/NIC slots provide flexibility for an array of AI compute applications with any throughput or configuration requirements. In addition, the semi-rugged frame design and extended operating temperature ranges make the 4U Pro system ideal for edge or mobile compute environments outside of the comfort of the datacenter.
The OSS 4U Pro GPU Accelerator System connects to one or multiple host nodes to add 8 PCIe Gen4 x16 expansion slots for the latest NVIDIA A100 Tensor Core GPUs. The A100 GPUs can be used individually or linked physically using an NVIDIA® NVLink™ Bridge to take advantage of NVLink 600 GB/s interconnect throughput. The 4U Pro system uses up to four PCIe Gen4 x16 Host Bus Adapters to bring the data into and out of the compute accelerator at speeds up to 128 GB/s. 4U Pro advanced features including redundant AC or DC inlet power, IPMI system monitoring, dynamic fan speed control. Configurable host/NIC slots provide flexibility for an array of AI compute applications with any throughput or configuration requirements. In addition, the semi-rugged frame design and extended operating temperature ranges make the 4U Pro system ideal for edge or mobile compute environments outside of the comfort of the datacenter.
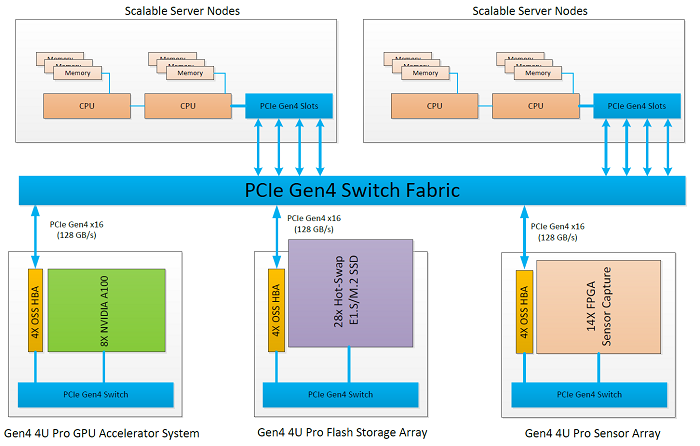
To match the scalable power of GPU compute expansion, the system architecture must also account for and scale the data collection, storage, and communication. For real-time AI inferencing applications, the speed of the data processing must be met by the speed in which the data is collected, stored, and communicated. In the same way that the compute power is scaled out through the addition of GPU nodes, the data capture, storage, and networking can be scaled by adding FPGA sensor arrays, high speed NVMe storage, and NICs respectively. By putting each of the key AI workflow building blocks on the same PCIe fabric, the host nodes can utilize NVIDIA GPUDirect RDMA and other pieces of the composable NVIDIA software stack to dynamically allocate resources and build a sustained, optimized, and complete AI workflow throughput.
The 4U Pro 16-Slot Expansion System connects to the same host nodes to add 16 PCIe Gen4 x8 expansion slots for single-width FPGA, NVMe, or NIC scale out. This configuration of the 4U Pro system allows scalable expansion of the PCIe fabric as a sensor, flash storage, or NIC array. The 4U Pro as a flash storage array can use 16 of the OSS PCIe Gen4 Dual E1.S/M.2 Carrier cards for 32 total PCIe Gen4 x4 NVMe drives. The individually hot-swappable NVMe drives allow new datasets to be securely transported and rapidly added to the AI compute fabric. The 4U Pro as a converged appliance can combine the power of the NVIDIA A100 GPU with NVMe storage, FPGA sensor capture, and high-speed NIC in one 4U enclosure for scalable converged compute nodes in a dense form factor. The flexibility, optimized PCIe Gen4 routing, and advanced features of the 4U Pro system make it a key building block in scaling AI compute platforms.
The need for modular real-time compute power will continue to grow as the availability and size of data compounds. OSS designs and manufactures the high-performance expansion nodes to meet this challenge in the 4U Pro system. OSS is an industry leader in high-performance edge computing, meeting the no-compromise nature of edge environments in optimized systems.
Disclaimer: This article may contain forward-looking statements based on One Stop Systems, Inc.’s current expectations and assumptions regarding the company’s business and the performance of its products, the economy, and other future conditions and forecasts of future events, circumstances and results.
