
In this video from SC16, Ben Sander from AMD presents: HIP and CAFFE Porting and Profiling with AMD’s ROCm. “We are excited to present ROCm, the first open-source HPC/Hyperscale-class platform for GPU computing that’s also programming-language independent. We are bringing the UNIX philosophy of choice, minimalism and modular software development to GPU computing. The new ROCm foundation lets you choose or even develop tools and a language run time for your application. ROCm is built for scale; it supports multi-GPU computing in and out of server-node communication through RDMA.”
Slidecast: For AMD, It’s Time to ROCm!
September 15, 2016 by

“AMD has been away from the HPC space for a while, but now they are coming back in a big way with an open software approach to GPU computing. The Radeon Open Compute Platform (ROCm) was born from the Boltzmann Initiative announced last year at SC15. Now available on GitHub, the ROCm Platform bringing a rich foundation to advanced computing by better integrating the CPU and GPU to solve real-world problems.”
HSA 1.1 Specification Adds Multi-Vendor Architecture Support
June 4, 2016 by

The Heterogeneous System Architecture (HSA) Foundation has released the HSA 1.1 specification, significantly enhancing the ability to integrate open and proprietary IP blocks in heterogeneous designs. The new specification is the first to define the interfaces that enable IP blocks from different vendors to communicate, interoperate and collectively compose an HSA system.
An HSA Overview
February 9, 2014 by
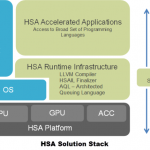
Over at the Stream Computing Blog, Vincent Hindriksen has posted an overview of the Heterogeneous Systems Architecture (HSA). “HSA changes the way memory is handled by eliminating a hierarchy in processing-units. In a hUMA architecture, the CPU and the GPU (inside the APU) have full access to the entire system memory.”
White Paper Looks at New AMD Compute Core Implementation
January 16, 2014 by
In a new white paper, AMD redefines the Compute Core as “Any core capable of running at least one process in its own context and virtual memory space, independently from other cores.” It’s a fascinating look into the new Kaveri chip and HSA.
HSA Heterogeneous System Architecture Overview
December 1, 2013 by

The HSA Foundation seeks to create applications that seamlessly blend scalar processing on the CPU, parallel processing on the GPU, and optimized processing on the DSP via high bandwidth shared memory access enabling greater application performance at low power consumption.

