Basic optimization techniques that include an understanding of math functions and how to simplify can go a long way towards better performance. “When optimizing for a parallel SIMD system such as the Intel Xeon Phi coprocessor, it is also important to make sure that the results match the scalar system. Using vector data may cause parts of the computer program to be re-written, so that the compiler can generate vector code.”
Financial Services and Low Latency with Intel Xeon Phi
November 19, 2015 by

“With high frequency trading becoming so important, the overall system performance, starting with the acquisition of the data from various markets through to the buy or sell decision relies on low latency between various parts of the system. The feed handlers, which accept the data in various formats, can be multithreaded and take advantage of coprocessors such as the Intel Xeon Phi. The NIC on a system waits for the packets to arrive and can then the information to a specified core on the Intel Xeon Phi coprocessor system for processing.”
DDN Sets World Record STAC Performance
July 28, 2015 by
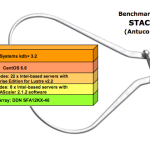
Today DDN announced record performance on the Securities Technology Analysis Center (STAC) benchmark. Using the company’s EXAScaler storage solution, DDN set new public records for multiple workload types and sizes, including large and small workloads as well as I/O and compute-intensive workloads.
Interview: How Univa Short Jobs Brings Low Latency to Financial Services
June 22, 2015 by

With the launch of Univa Small Jobs add-on for Univa Grid Engine, the company, the company offers “the world’s most efficient processing and lowest latency available for important tasks like real-time trading, transactions, and other critical applications.” To learn more, we caught up with Univa President & CEO Gary Tyreman.

