Parallelism helps applications make the best use of processors on single or multiple devices. However, parallelism implementation itself can prove a challenging task. In this video, Mike Voss, principal engineer with the Core and Visual Computing Group at Intel discusses the benefits of Intel® Threading Building Blocks (Intel® TBB), a C++ library, and how it can simplify the work of adding parallelism without the need to probe into threading details.
Vectorization Steps
May 26, 2016 by
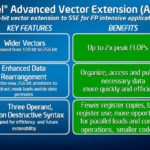
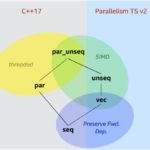
The process to vectorize application code is very important and can result in major performance improvements when coupled with vector hardware. In many cases, incremental work can mean a large payoff in terms of performance. “When applications that have successfully been implemented on supercomputers or have made use of SIMD instructions such as SSE or AVX are excellent candidates for a methodology to take advantage of modern vector capabilities in servers today.”
Why Parallelism?
April 21, 2016 by

“As clock speeds for CPU’s have not been increasing as compared to a decade ago, chip designers have been enhancing the performance of both CPUs, such as the Intel Xeon and the Intel Xeon Phi coprocessor by adding more cores. New designs allow for applications to perform more work in parallel, reducing the overall time to perform a simulation, for example. However, to get this increase in performance, applications must be designed or re-worked to take advantage of these new designs which can include hundreds to thousands of cores in a single computer system.”
Video: Bill Dally on Scaling Performance in the Post-Dennard Era
February 4, 2016 by

“It was indicated in my keynote this morning there are two really fundamental challenges we’re facing in the next two years in all sorts of computing – from supercomputers to cell phones. The first is that of energy efficiency. With the end of Dennard scaling, we’re no longer getting a big improvement in performance per watt from each technology generation. The performance improvement has dropped from a factor of 2.8 x back when we used to scale supply voltage with each new generation, now to about 1.3 x in the post-Dennard era. With this comes a real challenge for us to come up with architecture techniques and circuit techniques for better performance per watt.”
Nested Parallelism
July 30, 2015 by

The benefits of nested parallelism on highly threaded applications can be determined and quantified. With the number of cores in both the host CPU (Intel Xeon) and the coprocessor (Intel Xeon Phi) continues to increase, much thought must be given to minimizing the thread overhead when many threads need to be synchronized, as well as the memory access for each processor (core). Tasks that can be spread across an entire system to exploit the algorithm’s parallelism, should be mapped to the NUMA node to make them more efficient.
