

Murali Emani from Argonne National Lab
In this special guest feature, Murali Emani from Argonne writes that a team of scientists from DoE labs have formed a working group called MLPerf-HPC to focus on benchmarking machine learning workloads for high performance computing.
This group is closely associated with the MLPerf organization. The major effort is driven from DoE labs namely LBNL/NERSC, Argonne and Oak Ridge. We have significant interest and regular participation from the industry such as Cray, IBM, Nvidia, etc. We presented a poster on the initial benchmark results at the ECP Annual Meeting this year.
Introduction:
High-performance computing is seeing an upsurge in workloads with data on an unprecedented scale from massive simulations. Machine learning (ML) and Deep Learning (DL) models are increasingly being used in scientific applications in domains such as cosmology, particle physics, biology with tasks of image detection, segmentation, synthetic data generation and more. Alongside, there is an emerging trend of including diverse hardware compute resources such as many-core, multi-core, heterogeneous and AI-specific accelerators. It is critical to understand the performance of deep learning models on HPC systems in the exascale era and beyond. With evolving system architectures, hardware and software stacks, diverse ML workloads, and data, it is important to understand how these components interact with each other. As machine learning (ML) is becoming a critical component to help run applications faster, improve throughput and understand the insights from the data generated from simulations, benchmarking ML methods with scientific workloads at scale will be important as we progress towards next generation supercomputers. In particular, it is important to understand and reason the following questions that cater to scientific workloads.
- Why are standard HPC benchmarks needed for ML?
- What capabilities are missing in current benchmark suites to address ML and HPC workloads
- How benchmarks could be used to characterize systems to project future system performance such that representative benchmarks would be critical in designing future HPC systems that run ML workloads.
- What are the challenges in creating benchmarks that would be useful?
- Fast-moving field where representative workloads change with state-of-the-art
- On-node compute characteristics vs off-node communication characteristics for various training schemes
- Big datasets, I/O bottlenecks, reliability, MPI vs alternative communication backends
- Complex workloads where model training/inference might be coupled to simulations / high-dimensional data or Hyperparameter optimization, Reinforcement learning frameworks
- Availability and access to scientific datasets
- What metrics would help in comparing different systems and workloads
- How do we design benchmarks capable of characterizing HPC systems’ suitability for ML/DL workloads?
- Probably need to enumerate the types of workloads that are emerging in practice
- How do the needs of HPC facilities/labs differ from industry
- How to integrate AI in HPC workflows
- How well does the current landscape of emerging benchmarks represent industry/science use-cases?
- MLPerf, Deep500, BigData bench, AI Matrix (Alibaba)
The MLPERF-HPC working group poster is available for download
Towards this, a new working group within MLPerf (www.mlperf.org) was initiated. Named MLPerf-HPC, this working group is currently working on and developing solutions for ML benchmarking on Supercomputers. Key members who helped this initiative are Steve Farrell (LBNL/NERSC), Jacob Balma (Cray/HPE), Abid Malik (BNL), Murali Emani (ANL/ALCF). Also, there is active participation from 75+ members from various labs, companies, startups, universities such as LBNL, ANL, ORNL, BNL, Cray, IBM, Cerebras, NVIDIA, Intel, Indiana University.
Goals:
This group aims to create an HPC ML benchmark suite, that will help:
- Better understand the model-system interactions
- Better understand the deep learning workloads, optimize them and identify potential bottlenecks
- Quantify the scalability for different deep learning methods, frameworks and metrics on hardware diverse HPC systems
The initial target systems identified are
(i) Cori at NERSC: 30 petaflops, 2,388 Intel Xeon processor nodes, 9,688 Intel Xeon Phi (KNL) nodes Cray XC40
(ii) Theta at ALCF: 11.69 petaflops, 4,392-node Intel Xeon, Cray XC40
(iii) Summit at OLCF : 200 petaflops, 4,60-node IBM Power9 – Nvidia GPU
A list of preliminary candidate workloads selected are: (i) Cosmoflow (ii) Climate segmentation, (iii) Language modeling on OpenWebText dataset and (iv) Large scale multi-label image classification on TenCent dataset.
Activities:
The group is involved in technical outreach activities and two such are presented here.
(i) Birds of a feather (BoF) session at Supercomputing (SC’19):
The group organized the BoF session “Benchmarking Machine Learning Ecosystem on HPC Environment”. More than 60 SC19 attendees attended BoF. One noticeable attendee was, Dr. Geffrey Fox, who received the Kennedy Award at SC19. The BoF was received very well by the participants. People from academia and HPC industry working in machine learning showed the need for such open discussion and also appreciated the work done by the MLPerf group in this area. The discussion started with an introductory talk by the session chair Murali Emani from Argonne National Lab. He talked about the need for benchmarking for machine learning using HPC. It was followed by five short talks from David Kantar (MLPerf/Google), Steve Farrell (LBNL/NERSC), Sam Jackson (STFC/UK), Sergey Serebryakov (HPE), and Natalia Vassileva (Cerebras).

The talks presented academic/government research lab and industrial point of view on the need for benchmarks for machine learning. Later, the house was opened for a broad discussion. The session was coordinated by Steve Farrell from LBNL. The questions were posed to the panelists, consisting of the people who gave the talk. The questions were related to the need and type of models that need to be included in the benchmark suite, performance metrics for evaluation, and open source data set for training and testing of the machine learning models on HPC environment. The same questions were also posed to the audience for their feedback. The panelist and the audience talked about the similar ongoing efforts in this area and how we can learn from these efforts. The attendee later went to the panelist for one to one discussion for their specific needs in this area. To continue this effort, we are working towards another BoF session in SC20 next year.
(ii) Poster at the ECP Annual Meeting 2020:
The group presented the preliminary scalability results for two applications namely Climate segmentation and Cosmoflow on three target systems, Cori, Theta and Summit. The poster is titled “Exploring Deep Learning for Science Benchmarks on DOE Supercomputers” by Aristeidis Tsaris (ORNL), Jacob Balma (HPE), Murali Emani (ANL/ALCF), Steve Farrell (LBNL/NERSC), Geoffrey C Fox (Indiana University), Yin Junqi (ORNL), Thorsten Kurth (Nvidia), Abid Malik (BNL), Prabhat (LBNL/NERSC) Mallikarjun Shankar (ORNL/OLCF), Venkatram Vishwanath (ANL/ALCF).
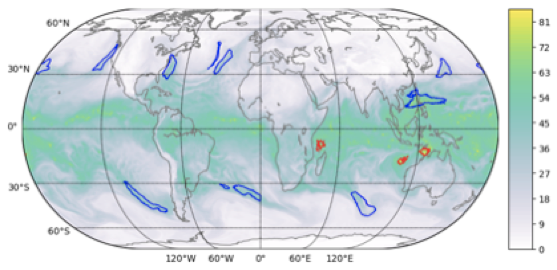 (a) Climate Segmentation: This application deals with Segmentation of extreme weather phenomena in climate simulation (768 x 1152 x 16 image shape). Reference implementation for the climate segmentation benchmark, based on the Exascale Deep Learning for Climate Analytics codebase here: https://github.com/azrael417/ClimDeepLearn, and the paper is available at https://arxiv.org/abs/1810.01993.
(a) Climate Segmentation: This application deals with Segmentation of extreme weather phenomena in climate simulation (768 x 1152 x 16 image shape). Reference implementation for the climate segmentation benchmark, based on the Exascale Deep Learning for Climate Analytics codebase here: https://github.com/azrael417/ClimDeepLearn, and the paper is available at https://arxiv.org/abs/1810.01993.
This benchmark is characterized by high-dimensional inputs and multi-label targets, 16-channel 2D images of size (768, 1152, 16), 3-class per-pixel and large dataset (20 TB) stresses I/O subsystem. The preliminary results demonstrate the scalability for a smaller representative data subset.
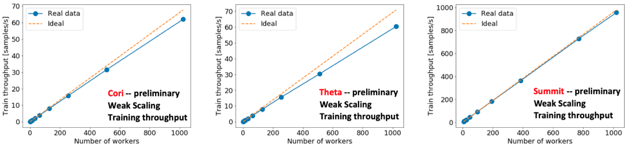
The measurements on target systems with mini-dataset observed are:
- Cori: 1.33 PF/s peak, 1.14 PF/s sust [FP32]
- Theta: 1.11 PF/s peak, 1.09 PF/s sust [FP32]
- Summit: 170 nodes (x6 v100s) 48.08 PF/s peak, 38.71 PF/s sust [FP16]
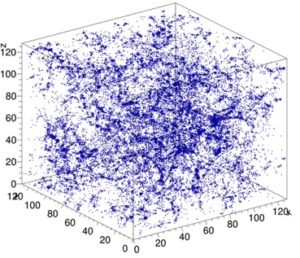 (b) Cosmoflow: This is an implementation of the CosmoFlow 3D convolutional neural network for benchmarking. It aims to predict cosmology parameters from whole-universe dark matter simulations (128 x 128 x 128 x 4 crops). This benchmark is written in TensorFlow with the Keras API and uses Horovod for distributed training.The paper is available at arXiv:1810.01993.
(b) Cosmoflow: This is an implementation of the CosmoFlow 3D convolutional neural network for benchmarking. It aims to predict cosmology parameters from whole-universe dark matter simulations (128 x 128 x 128 x 4 crops). This benchmark is written in TensorFlow with the Keras API and uses Horovod for distributed training.The paper is available at arXiv:1810.01993.
The characteristics of CosmoFlow are:
- Data-Parallel implementation across 3D Convolutions
- Multi-channel Volumetric input data stresses on-node bandwidths and memory capacities
- Communication patterns unique to convolutional model-parallelism
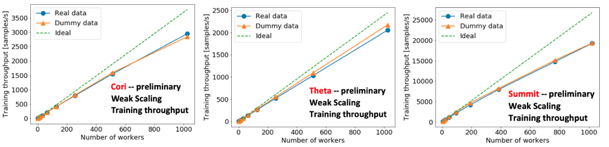
The measurements observed on target systems are:
- Cori: 1024 KNL nodes, 78% scaling efficiency
- Theta: 1024 KNL nodes, 84% scaling efficiency
- Summit: 170 nodes (x6 v100s), 72% scaling efficiency
As part of future work, we aim to focus on:
(a) Systematic study of the two benchmarks on the 3 target systems (b) Finalize metrics collection and software tool for system performance (flops, I/O, communication) across all 3 systems, (c) Get the language modeling and the Image classification benchmark up and running (d) Identify and pursue commonalities with main track MLPerf, best practices for data, model and pipelining parallelism (e) Use our benchmarks to evaluate next-generation HPC systems (f) Update suite with new benchmarks.
The poster is available at https://drive.google.com/file/d/1AUoDn_noMZL6MupIgcPXGALbSPAMLdQq/view
How to join the group:
We welcome anyone interested in related topics to join this group by sending an email to mlperf-hpc@googlegroups.com. We meet every Monday at noon PST over BlueJeans.
Google group website is: https://groups.google.com/forum/#!forum/mlperf-hpc.
Murali Emani is an Assistant Computer Scientist in the Data Sciences group with the Argonne Leadership Computing Facility (ALCF) at Argonne National Laboratory. Prior, he was a Postdoctoral Research Staff Member at Lawrence Livermore National Laboratory, US. Murali obtained his PhD and worked as a Research Associate at the Institute for Computing Systems Architecture the School of Informatics, University of Edinburgh, UK. His primary research focus lies in the intersection of systems and machine learning. Research interests include Parallel programming models, Hardware accelerators for ML/DL, High Performance Computing, Scalable Machine Learning, Runtime Systems, Performance optimization, Emerging HPC architectures, Online Adaptation.
Sign up for our insideHPC Newsletter
