
Third-party performance benchmarks show CPUs with HBM2e memory now have sufficient memory bandwidth and computational capabilities to match GPU performance on many HPC and AI workloads.
Recent Intel and third-party benchmarks now provide hard evidence that the upcoming Intel® Xeon® processor Max Series, with fast, high bandwidth HBM2e memory and Intel® Advanced Matrix Extensions, can match the performance of GPUs for many AI and HPC workloads. For many memory bandwidth bound applications, GPUs no longer outperform CPUs simply because they have a faster memory system. HBM2e memory for CPUs levels the playing field, making architectural differences the deciding factor in deciding which of the two devices is the preferred platform for a given workload.
The numbers tell the story as the addition of 64GB of on-package HBM2e memory increases bandwidth available to the forthcoming Intel Xeon processor Max Series with HBM2e high bandwidth memory to approximately 1.22 TB/s, or by four times when compared to a similar Intel Xeon CPU with eight DDR5-4800 channels. [1]
Achieving GPU Performance on AI Workloads
The performance of bandwidth limited workloads is obviously dictated by the bandwidth of the memory subsystem. Historically, GPUs memory systems could deliver significantly more bytes per second to their computational units, which gave GPUs the ability to run many — but not all — memory bandwidth limited workloads much faster than CPUs. (The “not all” is important to HPC workloads and will be discussed below.)
This history made AI the de facto workload performance winner for GPUs.
GPUs are fantastic for running data parallel workloads where every thread executes the same instruction in lockstep. This is referred to as the single instruction, multiple data execution (SIMD) architecture. For example, the very time-consuming training of AI models provides an excellent example of the trade-offs between computation, memory performance, and amount of parallelism in the problem. [2] Bulk inference operations (e.g., using the trained model to make predictions) also exhibit the same trade-offs.
Correspondingly, modern floating-point units have significantly outpaced memory performance for decades. [3] This explains why the training and evaluation of many AI models can very quickly become memory bandwidth bound because the computational units can process data faster than the memory system can fetch data.
The advent of deep learning quickly increased the complexity of the AI models and the types of computations performed inside the AI model. In response, GPU vendors added special instructions to their instruction set architectures (ISA) to speed the processing of the popular deep-learning models. Convolutional neural networks are one example. The advent of hardware accelerated reduced-precision arithmetic is another. Such ISA changes, along with the unavoidable fact that training more complex models generally requires big increases in the training set size [4] again made memory bandwidth the gating performance factor for many AI workloads.
The forthcoming Intel Xeon processor Max Series have made all this past history as Intel has incorporated these technology advantages into a CPU solution. As can be seen in the AlphaFold2 benchmark results below, the combination of HBM2e memory and Intel Advanced Matrix Extensions (Intel® AMX) provide a massive performance uplift on an important problem. According to the National Library of Medicine, “AlphaFold2 was the star of CASP14, the last biannual structure prediction experiment. Using novel deep learning, AF2 predicted the structures of many difficult protein targets at or near experimental resolution.” [5]
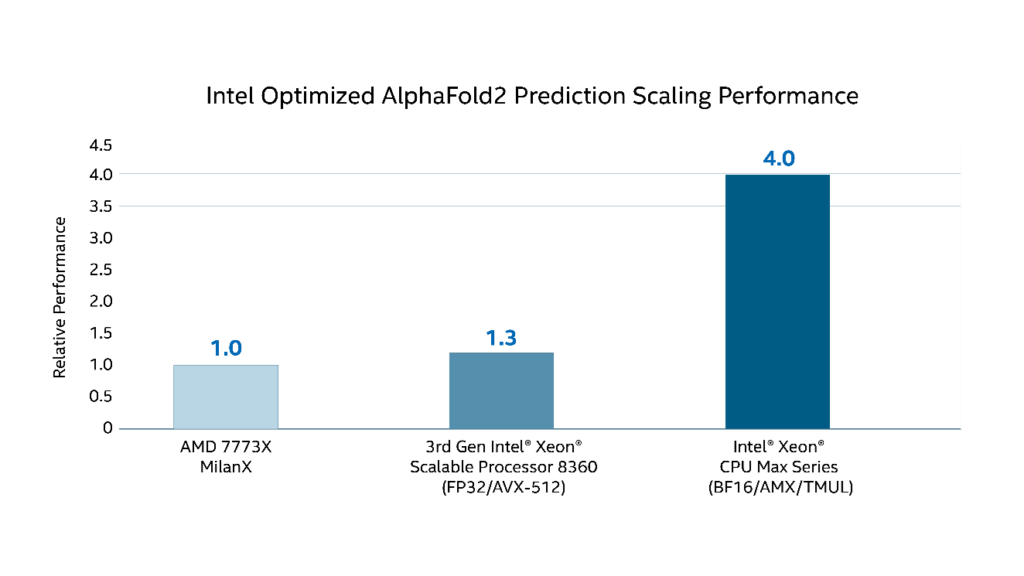
Figure 1. Speedup observed with the Intel Xeon processors Max Series using HBM2e memory and various AI-oriented ISA features such as Intel AMX.
The AlphaFold2 benchmark results also show that the Intel Xeon processor Max Series also outpace other CPUs. Vikram Saletore (director and principal engineer in the Super Compute Group at Intel) explains, “The AphaFold2 results reflect how good these processors will be for both cloud and HPC users”.
The DeepCAM training performance reported by Intel at ISC’22 demonstrates faster performance compared to an NVIDIA A100 80GB GPU. Overall, the DeepCAM results (bottom graph below) show an up to 3.6× improvement over the baseline EPYC 7763 [6]. The modified DeepLab v3 AI model with 57 million trainable parameters and is trained on batches of very large 2D images, 64MB. These benchmarks have a significant PCIe and I/O component during training that affect GPU performance.
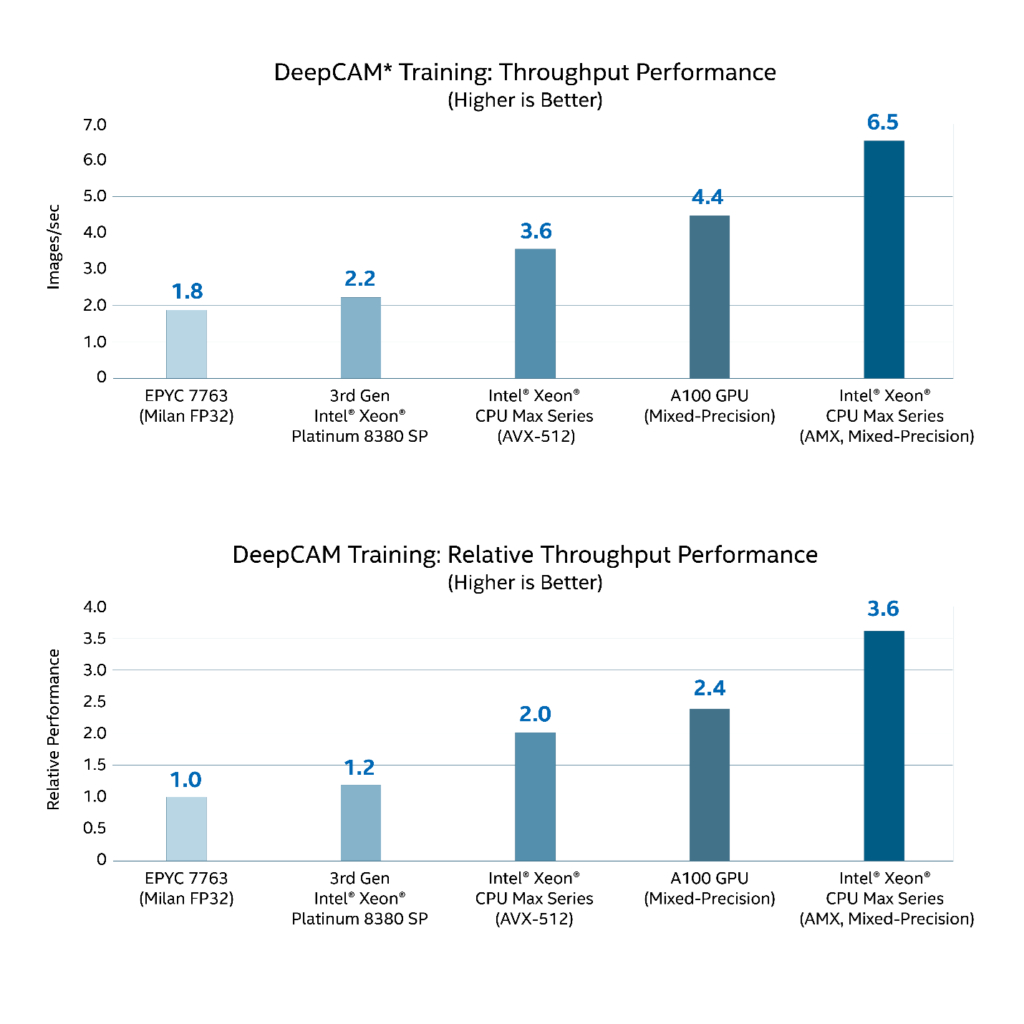
Figure 2. *DeepCAM throughput performance results [19]. Training throughput is not the primary metric of MLPerf Training. “Unverified performance Gains on MLPerf™ HPC-AI v 0.7 DeepCAM Training benchmark (https://github.com/mlcommons/hpc/tree/main/deepcam) using Pytorch. Result not verified by MLCommons Association. Unverified results have not been through an MLPerf™ review and may use measurement methodologies and/or workload implementations that are inconsistent with the MLPerf™ specification for verified results. The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
In his ISC’22 keynote, Intel’s Jeff McVeigh (vice president and general manager of the Super Compute Group at Intel Corporation) cited significant performance improvements across key HPC use cases. “When comparing 3rd Gen Intel Xeon Scalable processors to the upcoming Intel Xeon processor Max Series,” McVeigh observed, “we are seeing two- to three-times performance increases across weather research, energy, manufacturing, and physics workloads” [7] [8]
When comparing 3rd Gen Intel® Xeon® Scalable processors to the upcoming Intel Xeon processor Max Serues, we are seeing two- to three-times performance increases across weather research, energy, manufacturing, and physics workloads. – Jeff McVeigh, vice president and general manager of the Super Compute Group at Intel Corporation
Commercial HPC is Included – Ansys Fluent
Ansys Fluent is a particularly high-profile use case that is of interest to many commercial HPC users. Fluent is an industry-leading fluid simulation software that is known for its advanced physics modeling capabilities and high accuracy. [9]
At ISC’22, Ansys CTO Prith Banerjee summarized the Ansys results by noting that the Intel Xeon processor Max Series delivered up to 2× performance increase on real-world workloads from Ansys Fluent and ParSeNet. [10] [11] This speedup is reflected across a broad spectrum of Fluent benchmarks:
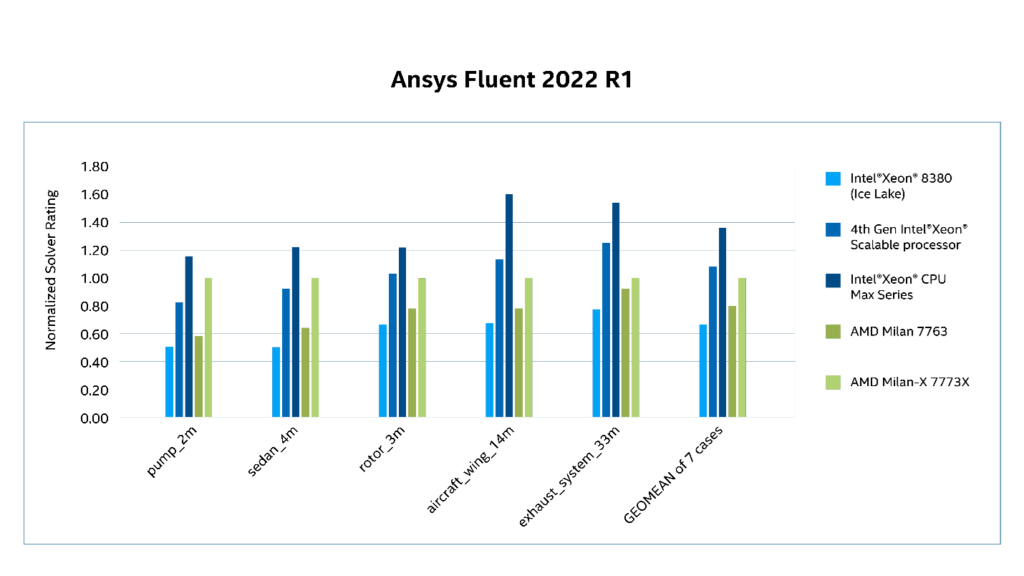
Figure 3. Ansys Fluent results determined by Intel and cross-verified with third-party benchmarks results. [12]
We are excited to see Intel driving HPC to new heights with the Intel Xeon processor Max Series. In early testing of our Fluent CFD software on these processors, we’re seeing up to 2.2X performance gains over the previous generation of Intel Xeon Platinum processors due to extremely high memory bandwidth from HBM as well as AVX-2 support and high core frequency. – Wim Slagter, Strategic Partnerships Director at Ansys
The ParSeNet performance challenges GPU AI dominance with a 1.8× speedup in training performance compared to an NVIDIA A100 GPU. ParSeNet is a parametric surface fitting network for 3d point clouds.
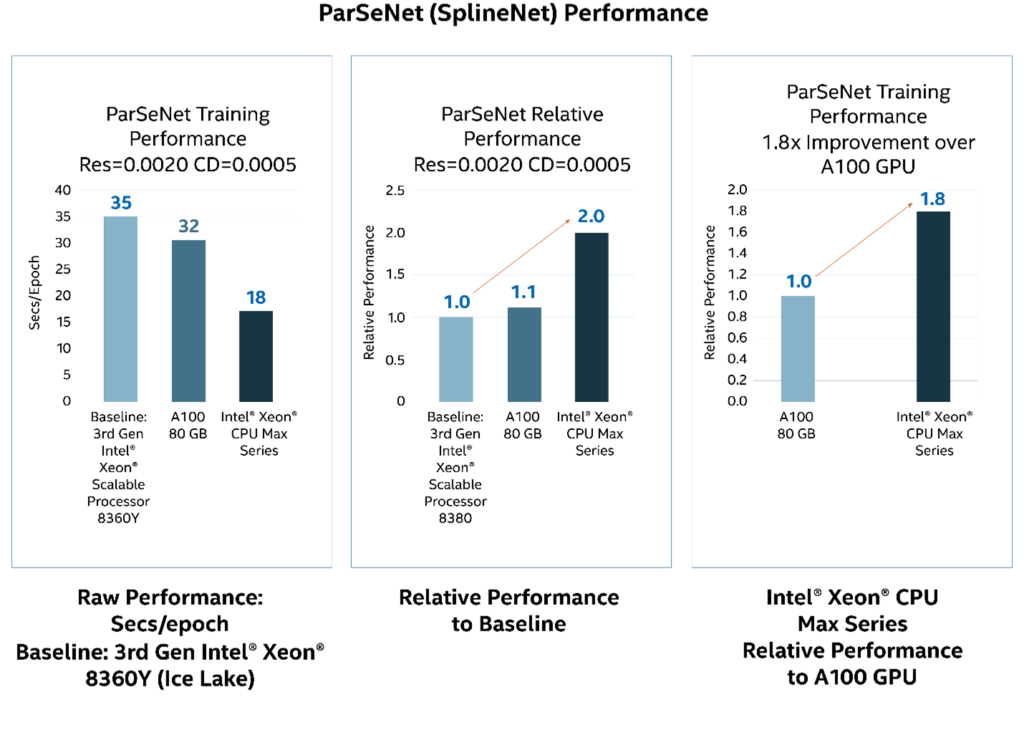
Figure 4. ParSeNet training performance determined by Intel and cross-verified with third-party benchmarks results. [15]
The combination of HBM2e memory and Intel’s ISA improvements can make these processors the preferred AI and HPC platform. Based on industry trends, Saletore takes this further when he predicts, “After a lot of talk and little movement over recent years, we’re starting to see real movement towards the integration of AI into HPC workloads. With the upcoming Intel Xeon processor Max Series, Intel makes a compelling argument that our CPUs are not just viable for this new integrated class of workloads, but these processors are the desired platform for these workloads.”
After a lot of talk and little movement over recent years, we’re starting to see real movement towards the integration of AI into HPC workloads. With the upcoming Intel Xeon processor Max Series, Intel makes a compelling argument that our CPUs are not just viable for this new integrated class of workloads, but these processors are the desired platform for these workloads. — Vikram Saletore
Saletore’s belief is solidly grounded in seminal research by CERN and other research organizations. CERN, for example, demonstrated that AI-based models can act as orders-of-magnitude-faster replacements for computationally expensive tasks in an HPC simulation, while still maintaining a remarkable level of accuracy. [16]
Cosmoflow results using Tensorflow shown in Figure 5 (and ParSeNet shown previously in Figure 4) support Saletore’s prediction.
The CosmoFlow training application benchmark is part of the MLPerf HPC benchmark suite. It involves training a 3D convolutional neural network for N-body cosmology simulation data to predict physical parameters of the universe. [17] The benchmark built on top of the TensorFlow framework makes heavy use of convolution and pooling primitives. [18] In total, the model contains approximately 8.9 million trainable parameters and the training throughput performance is measured.
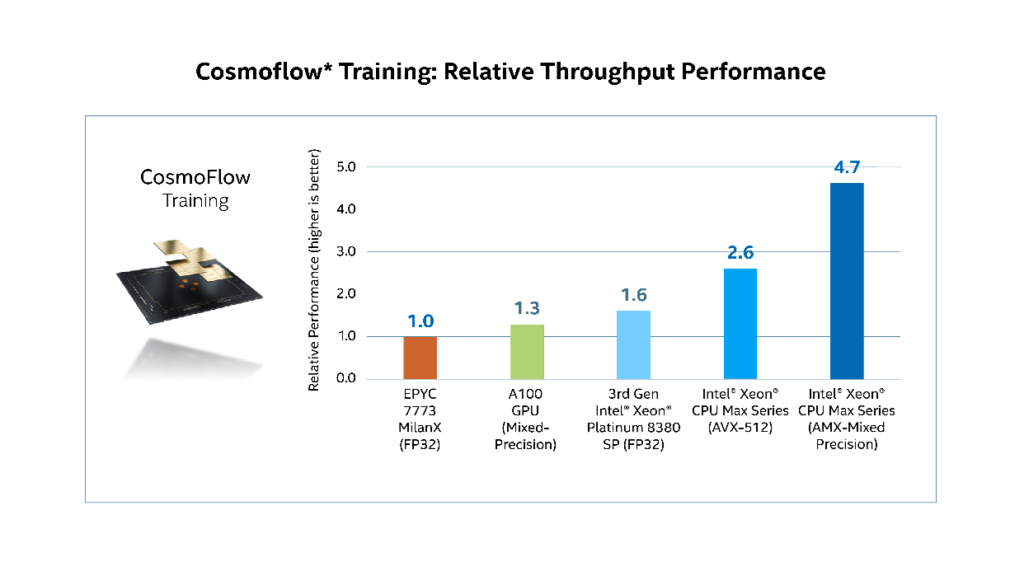
Figure 5. *Cosmoflow relative throughput performance results [20]. Training throughput is not the primary metric of MLPerf Training *“Unverified performance Gains on MLPerf™ HPC-AI v 0.7 CosmoFlow Training benchmark (https://github.com/mlcommons/hpc/tree/main/cosmoflow) using Tensorflow. Result not verified by MLCommons Association. Unverified results have not been through an MLPerf™ review and may use measurement methodologies and/or workload implementations that are inconsistent with the MLPerf™ specification for verified results. The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
A huge challenge with GPUs lies in mapping HPC applications and numerical algorithms to the GPU SIMD architecture. The fundamental problem is that SIMD architectures (e.g., GPUs) impose limitations that don’t exist when programming the general-purpose MIMD architecture implemented by CPUs. Further, many HPC and AI workloads do not need the massive parallelism of GPUs. With Intel Xeon processor Max Series, users need only match the parallelism and architecture of the device to the workload.
Conclusion
For many cloud and on-premises datacenters, giving users access to GPU-accelerated performance without requiring specific GPU-enabled software is very attractive and cost-effective solution. Third-party benchmarks independently confirm that the upcoming Intel Xeon processor Max Series with high bandwidth memory and Intel Advanced Matrix Extensions can match the performance of GPUs for many HPC and AI workloads. At the same time, Intel benchmarks demonstrate that Intel Xeon processor Max Series are an attractive solution because they can deliver an across-the-board 2× to 3× increase in HPC and AI workload performance compared to the previous 3rd generation Intel Xeon Scalable processors.
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more on the Performance Index site.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Intel does not control or audit third party data. You should consult other sources for accuracy.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
[1] https://www.tomshardware.com/news/intel-fires-up-xeon-max-cpus-gpus-to-rival-amd-nvidia
[2] https://www.amazon.com/CUDA-Application-Design-Development-Farber/dp/0123884268
[4] https://proceedings.neurips.cc/paper/1987/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf
[5] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8592092/
[6] Intel notes, “Unverified performance Gains on MLPerf™ HPC-AI v 0.7 DeepCAM Training benchmark using optimized Pytorch 1.11. Result not verified by MLCommons Association. Unverified results have not been through an MLPerf™ review and may use measurement methodologies and/or workload implementations that are inconsistent with the MLPerf™ specification for verified results. The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.”
[8] As measured by the following:
- CloverLeaf
- Test by Intel as of 04/26/2022. 1-node, 2x Intel® Xeon® Platinum 8360Y CPU, 72 cores, HT On, Turbo On, Total Memory 256GB (16x16GB DDR4 3200 MT/s ), SE5C6200.86B.0021.D40.2101090208, Ubuntu 20.04, Kernel 5.10, 0xd0002a0, ifort 2021.5, Intel MPI 2021.5.1, build knobs: -xCORE-AVX512 –qopt-zmm-usage=high
- Test by Intel as of 04/19/22. 1-node, 2x Pre-production Intel® Xeon® Processor Max Series >40 cores, HT ON, Turbo ON, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version EGSDCRB1.86B.0077.D11.2203281354, ucode revision=0x83000200, CentOS Stream 8, Linux version 5.16, ifort 2021.5, Intel MPI 2021.5.1, build knobs: -xCORE-AVX512 –qopt-zmm-usage=high
- OpenFOAM
- Test by Intel as of 01/26/2022. 1-node, 2x Intel® Xeon® Platinum 8380 CPU), 80 cores, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C6200.86B.0020.P23.2103261309, 0xd000270, Rocky Linux 8.5 , Linux version 4.18., OpenFOAM® v1912, Motorbike 28M @ 250 iterations; Build notes: Tools: Intel Parallel Studio 2020u4, Build knobs: -O3 -ip -xCORE-AVX512
- Test by Intel as of 01/26/2022 1-node, 2x pre-production Intel® Xeon® Processor Max Series, >40 cores, HT Off, Turbo Off, Total Memory 128 GB (HBM2e at 3200 MHz), pre-production platform and BIOS, CentOS 8, Linux version 5.12, OpenFOAM® v1912, Motorbike 28M @ 250 iterations; Build notes: Tools: Intel Parallel Studio 2020u4, Build knobs: -O3 -ip -xCORE-AVX512
- WRF
- Test by Intel as of 05/03/2022. 1-node, 2x Intel® Xeon® 8380 CPU, 80 cores, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode revision=0xd000270, Rocky Linux 8.5, Linux version 4.18, WRF v4.2.2
- Test by Intel as of 05/03/2022. 1-node, 2x Pre-production Intel® Xeon® Processor Max Series, >40 cores, HT ON, Turbo ON, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version EGSDCRB1.86B.0077.D11.2203281354, ucode revision=0x83000200, CentOS Stream 8, Linux version 5.16, WRF v4.2.2
- YASK
- Test by Intel as of 05/9/2022. 1-node, 2x Intel® Xeon® Platinum 8360Y CPU, 72 cores, HT On, Turbo On, Total Memory 256GB (16x16GB DDR4 3200 MT/s ), SE5C6200.86B.0021.D40.2101090208, Rocky linux 8.5, kernel 4.18.0, 0xd000270, Build knobs: make -j YK_CXX=’mpiicpc -cxx=icpx’ arch=avx2 stencil=iso3dfd radius=8,
Test by Intel as of 05/03/22. 1-node, 2x Pre-production Intel® Xeon® Processor Max Series, >40 cores, HT ON, Turbo ON, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version EGSDCRB1.86B.0077.D11.2203281354, ucode revision=0x83000200, CentOS Stream 8, Linux version 5.16, Build knobs: make -j YK_CXX=’mpiicpc -cxx=icpx’ arch=avx2 stencil=iso3dfd radius=8
[9] https://www.ansys.com/resource-center/webinar/introduction-to-ansys-fluent
[11] Reference benchmarks:
- Ansys Fluent
-
- Test by Intel as of 2/2022 1-node, 2x Intel ® Xeon ® Platinum 8380 CPU, 80 cores, HT On, Turbo On, Total Memory 256 GB (16x16GB 3200MT/s, Dual-Rank), BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode revision=0xd000270, Rocky Linux 8.5 , Linux version 4.18, Ansys Fluent 2021 R2 Aircraft_wing_14m; Build notes: Commercial release using Intel 19.3 compiler and Intel MPI 2019u
- Test by Intel as of 2/2022 1-node, 2x pre-production Intel® Xeon® Processor Max Series, >40 cores, HT Off, Turbo Off, Total Memory 128 GB (HBM2e at 3200 MHz), pre-production platform and BIOS, CentOS 8, Linux version 5.12, Ansys Fluent 2021 R2 Aircraft_wing_14m; Build notes: Commercial release using Intel 19.3 compiler and Intel MPI 2019u8
-
- Ansys ParSeNet
-
- Test by Intel as of 05/24/2022. 1-node, 2x Intel® Xeon® Platinum 8380 CPU, 40 cores, HT On, Turbo On, Total Memory 256GB (16x16GB DDR4 3200 MT/s [3200 MT/s]), SE5C6200.86B.0021.D40.2101090208, Ubuntu 20.04.1 LTS, 5.10, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (2021.4-Product Build 20210904), oneDNN (v2.5.0)
- Test by Intel as of 04/18/2022. 1-node, 2x Intel® Xeon® Processor Max Series, 112 cores, HT On, Turbo On, Total Memory 128GB (HBM2e 3200 MT/s), EGSDCRB1.86B.0077.D11.2203281354, CentOS Stream 8, 5.16, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (2021.4-Product Build 20210904), oneDNN (v2.5.0)
-
[12] System configurations:
- Test by Intel as of 8/24/2022. 1-node, 2x AMD EPYC 7773X, HT On, Turbo On, NPS4,Total Memory 256 GB, BIOS ver. M10, ucode 0xa001224, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Fluent 2022R1
- Test by Intel as of 08/31/2022. 1-node, 2x Intel® Xeon® Scalable processor, codenamed Sapphire Rapids with HBM, HT ON, Turbo ON, SNC4, Total Memory 128 GB (HBM2e at 3200 MHz), BIOS Version SE5C7411.86B.8424.D03.2208100444, ucode 2c000020, CentOS Stream 8, kernel version 5.19.0-rc6.0712.intel_next.1.x86_64+server, Ansys Fluent 2022R1
- Test by Intel as of 8/24/2022. 1-node, 2x AMD EPYC 7763, HT On, Turbo On, NPS4,Total Memory 256 GB, BIOS ver. Ver 2.1 Rev 5.22, ucode 0xa001144, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Fluent 2022R1
- Test by Intel as of 09/02/2022. 1-node, 2x 4th Gen Intel® Xeon® Scalable Processor, HT ON, Turbo ON, SNC4, Total Memory 512 GB, BIOS Version EGSDCRB1.86B.0083.D22.2206290535, ucode 0xaa0000a0, CentOS Stream 8, kernel version 4.18.0-365.el8.x86_64, Ansys Fluent 2022R1
- Test by Intel as of 08/24/2022. 1-node, 2x Intel® Xeon® 8380, HT ON, Turbo ON, Quad, Total Memory 256 GB, BIOS Version SE5C6200.86B.0020.P23.2103261309, ucode 0xd000270, Rocky Linux 8.6, kernel version 4.18.0-372.19.1.el8_6.crt1.x86_64, Ansys Fluent 2022R1
[13] Supporting comment provided to Intel for this article.
[14] Based on Ansys internal measurements.
[15] Optimizations: Intel optimized Pytorch with Intel oneAPI, oneDNN (Neural Network Library), oneCCL (Collective Communication Library), and Intel MPI for distributed training, with 8 workers, affinized to Cores and HBM.
System configurations:
- Test by Intel as of 04/18/2022. 1-node, 2x Intel® Xeon® Platinum 8360Y, HT On, Turbo On, Total Memory 256GB (16x16GB DDR4 3200 MT/s [3200 MT/s]), SE5C6200.86B.0021.D40.2101090208, Ubuntu 20.04.1 LTS, 5.10.54+prerelease3012, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (2021.4-Product Build 20210904), oneDNN (v2.5.0) ), Using 8 Training workers affinized to CPU Cores and Memory.
- Test by Intel as of 04/18/2022. 1-node, GPU: 1x NVIDIA A100-80G PCIe, 2x Intel® Xeon® Platinum 8360Y, HT On, Turbo On, Total Memory 512GB (16x32GB DDR4 3200 MT/s [3200 MT/s]), SE5C6200.86B.0022.D08.2103221623, Ubuntu 20.04.1 LTS, 5.13.0-28-generic, ParSeNet (SplineNet), PyTorch 1.10.1, cuda11.3, cudnn8.2.0_0, openmp 2021.4.0, mkl 2021.4.0, Python 3.9.7
- Test by Intel as of 04/18/2022. 1-node, 2x 4th Gen Intel® Xeon Processor, HT On, Turbo On, Total Memory 128GB (8x16GB HBM2 3200MT/s [3200MT/s]), EGSDCRB1.86B.0077.D11.2203281354, CentOS Stream 8, 5.16.0-0121.intel_next.1.x86_64+server, ParSeNet (SplineNet), PyTorch 1.11.0, Torch-CCL 1.2.0, IPEX 1.10.0, MKL (2021.4-Product Build 20210904), oneDNN (v2.5.0), Using 8 Training workers affinized to CPU Cores and Memory.
[16] https://www.hpcwire.com/2018/08/14/cern-incorporates-ai-into-physics-based-simulations/
[17] https://proxyapps.exascaleproject.org/app/mlperf-cosmoflow/
[18] https://arxiv.org/abs/1808.04728
[19] DeepCAM System Configurations for Throughput: Training throughput is not the primary metric of MLPerf Training
- Test by Intel as of 04/07/2022. 1-node, 2x EPYC 7763, HT On, Turbo Off, Total Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS AMI 1.1b, ucode 0xa001144, OS Red Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-4), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl, Intel MPI 2021.5, ppn=4, LBS=16, ~64GB data, 16 epochs, Python3.8
- Test by Intel as of 04/07/2022. 1-node, 2x 3rd Gen Intel® Xeon® Platinum 8380 processor, 40 Cores, HT On, Turbo Off, Total Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS SE5C6200.86B.0022.D64.2105220049, ucode 0xd0002b1, OS Red Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-4), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB data, 16 epochs, Python3.8
- Test by Intel as of 04/13/2022. 1-node, 2x 3rd Gen Intel® Xeon® Scalable Processor 8360Y, 36 cores, HT On, Turbo On, Total Memory 256 GB (16 slots/ 16 GB/ 3200 MHz), NVIDIA A100 80GB PCIe (UUID: GPU-59998403-852d-2573-b3a9-47695dca0604), PICe ID 20B5, BIOS AMI 1.1b, ucode 0xd000311, OS Red Hat Enterprise Linux 8.4 (Ootpa), kernel 4.18.0-305.el8.x86_64, compiler gcc (GCC) 8.4.1 20200928 (Red Hat 8.4.1-1), https://github.com/mlcommons/hpc/tree/main/deepcam, 11.0 py3.7_cuda11.3_cudnn8.2.0_0, cudnn 8.2.1, cuda11.3_0, intel-openmp 2022.0.1 h06a4308_3633, LBS=4, ~64GB data, 16 epochs, python3.7
- Test by Intel as of 05/25/2022. 1-node, 2x Intel® Xeon® Processor Max Series, HT On, Turbo Off, Total Memory 128GB HBM and 1TB (16 slots/ 64 GB/ 4800 MHz, DDR5), BIOS EGSDCRB1.86B.0080.D05.2205081330, ucode 0x8f000320, OS CentOS Stream 8, kernel 5.18.0-0523.intel_next.1.x86_64+server, compiler gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-10), https://github.com/mlcommons/hpc/tree/main/deepcam, torch1.11.0a0+git13cdb98, AVX-512 FP32, torch-1.11.0a0+git13cdb98-cp38-cp38-linux_x86_64.whl, torch_ccl-1.2.0+44e473a-cp38-cp38-linux_x86_64.whl, intel_extension_for_pytorch-1.10.0+cpu-cp38-cp38-linux_x86_64.whl (AVX-512, AMX, BFloat16 Enabled), Intel MPI 2021.5, ppn=8, LBS=16, ~64GB data, 16 epochs, Python3.8
[20] Cosmoflow System Configurations for Throughput: Training throughput is not the primary metric of MLPerf Training:
- Test by Intel as of 10/7/2022. 1 node, 2x AMD EPYC 7773X 64-Core Processor, 64 cores, HT On, AMD Turbo Core On, Total Memory 512 GB (16 slots/ 32 GB/ 3200 MHz), BIOS M10, ucode 0xa001229, OS CentOS Stream 8, kernel 4.18.0-383.el8.x86_64, https://github.com/mlcommons/hpc/tree/main/cosmoflow, Intel TensorFlow 2.8.0, horovod 0.22.1, keras 2.8.0, OpenMPI 4.1.0, ppn=16, LBS=16, ~25GB data, 16 epochs, Python 3.8
- Test by Intel as of 06/16/2022. 1-node, 2x Intel® Xeon® Scalable Processor 8360Y, 36 cores, HT On, Turbo On, Total Memory 256 GB (16 slots/ 16 GB/ 3200 MHz), NVIDIA A100 80GB PCIe (UUID: GPU-59998403-852d-2573-b3a9-47695dca0604), PICe ID 20B5, BIOS AMI 1.1b, ucode 0xd000311, OS Red Hat Enterprise Linux 8.4 (Ootpa), kernel 4.18.0-305.el8.x86_64, compiler gcc (GCC) 8.4.1 20200928 (Red Hat 8.4.1-1), https://github.com/mlcommons/hpc/tree/main/cosmoflow, Tensorflow 2.6.0, keras 2.6.0, cudnn 8.2.1, horovod 0.24.2, LBS=16, ~25GB data, 16 epochs, Python 3.7
- Test by Intel as of 06/07/2022. 1-node, 2x Intel® Xeon® Scalable Processor 8380, 40 cores, HT On, Turbo On, Total Memory 512 GB (16 slots/ 32 GB/ 3200 MHz, DDR4), BIOS SE5C6200.86B.0022.D64.2105220049, ucode 0xd0002b1, OS Red Hat Enterprise Linux 8.5 (Ootpa), kernel 4.18.0-348.7.1.el8_5.x86_64, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AVX-512, FP32, Tensorflow 2.9.0, horovod 0.23.0, keras 2.6.0, oneCCL-2021.4, oneAPI MPI 2021.4.0, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8
- Test by Intel as of 10/18/2022. 1 node, 2x Intel® Xeon® Processor Max Series, HT On, Turbo On, Total Memory 128 HBM and 512 GB DDR (16 slots/ 32 GB/ 4800 MHz), BIOS SE5C7411.86B.8424.D03.2208100444, ucode 0x2c000020, CentOS Stream 8, kernel 5.19.0-rc6.0712.intel_next.1.x86_64+server, https://github.com/mlcommons/hpc/tree/main/cosmoflow, AVX-512, FP32, TensorFlow 2.6.0, horovod 0.23.0, keras 2.6.0, oneCCL 2021.5, ppn=8, LBS=16, ~25GB data, 16 epochs, Python 3.8

The CosmoFlow Training result label for the AMD chip is labeled 2.7, but the bar suggests this should be labeled 0.7.