Montreal, March 25 th, 2024 — Hydro Québec is now a partner of the Platform for Digital and Quantum Innovation of Quebec (PINQ²). As the administrator of Canada’s first IBM Quantum System One located at IBM ’s facility in Bromont, Quebec, PINQ² offers an innovative approach to computing for companies wishing to conduct research , […]
Bringing Personalized Medicine to Citizens
September 19, 2023 by Leave a Comment

Novo Genomics Healthcare start-up Novo Genomics is laying the foundation for personalized medicine in Saudi Arabia, with cutting-edge sequencing using the Lenovo Genomics Optimization And Scalability Tool (GOAST) architecture—based on Lenovo ThinkSystem SR630 V2 Servers powered by 3rd Gen Intel® Xeon® Scalable processors. The organization aims to harness genomics and multiomics to develop personalized […]
A New Way to Visualize Performance Optimization Tradeoffs
November 30, 2017 by
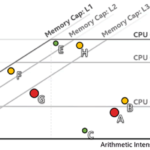
A valuable feature of Intel Advisor is its Roofline Analysis Chart, which provides an intuitive and powerful visualization of actual performance measured against hardware-imposed performance ceilings. Intel Advisor’s vector parallelism optimization analysis and memory-versus-compute roofline analysis, working together, offer a powerful tool for visualizing an application’s complete current and potential performance profile on a given platform.
Building Fast Data Compression Code with Intel Integrated Performance Primitives (Intel IPP) 2018
November 9, 2017 by

Intel® Integrated Performance Primitives (Intel IPP) is a highly optimized, production-ready, library for lossless data compression/decompression targeting image, signal, and data processing, and cryptography applications. Intel IPP includes more than 2,500 image processing, 1,300 signal processing, 500 computer vision, and 300 cryptography optimized functions for creating digital media, enterprise data, embedded, communications, and scientific, technical, and security applications.
OpenMP at 20 Moving Forward to 5.0
September 28, 2017 by

This year, OpenMP*, the widely used API for shared memory parallelism supported in many C/C++ and Fortran compilers, turns 20. OpenMP is a great example of how hardware and software vendors, researchers, and academia, volunteering to work together, can successfully design a specification that benefits the entire developer community.
Multicore Performance Challenges for Game Developers
June 8, 2017 by

Game developers face a unique challenge – how to make their graphics-heavy applications perform well across a very wide spectrum of hardware devices, not just high-end systems. So while an early version of a game might have been developed on some high-end system with 10 teraflops of CPU potential in a discrete graphics card, how do you scale it down to smaller consumer devices where optimization options are more limited?
The OpenMP API Celebrates 20 Years of Success
May 25, 2017 by
OpenMP is a good example of how hardware and software vendors, researchers, and academia, volunteering to work together, can successfully design a standard that benefits the entire developer community. Today, most software vendors track OpenMP advances closely and have implemented the latest API features in their compilers and tools. With OpenMP, application portability is assured across the latest multicore systems, including Intel Xeon Phi processors.
C++ Parallel STL Introduced in Intel Parallel Studio XE 2018 Beta
May 11, 2017 by
Parallel STL now makes it possible to transform existing sequential C++ code to take advantage of the threading and vectorization capabilities of modern hardware architectures. It does this by extending the C++ Standard Template Library with an execution policy argument that specifies the degree of threading and vectorization for each algorithm used.
Intel Advisor Roofline Analysis Finds New Opportunities for Optimizing Application Performance
April 27, 2017 by
Intel Advisor, an integral part of Intel Parallel Studio XE 2017, can help identify portions of code that could be good candidates for parallelization (both vectorization and threading). It can also help determine when it might not be appropriate to parallelize a section of code, depending on the platform, processor, and configuration it’s running on. Intel Advisor Roofline Analysis reveals the gap between an application’s performance and its expected performance.
Intel® VTune™ Amplifier Turns Raw Profiling Data Into Performance Insights
April 13, 2017 by
Discovering where the performance bottlenecks are and knowing what to do about it can be a mysterious and complex art, needing some very sophisticated performance analysis tools for success. That’s where Intel® VTune™ Amplifier XE 2017, part of Intel Parallel Studio XE, comes in.

