Today vScaler announced plans to showcase their HPC cloud platform March 15-16 at the upcoming Cloud Expo Europe Conference in London. Supported by two of its strategic technology partners – Aegis Data and Global Cloud Xchange, vScaler will showcase its application specific cloud platform, with experts on hand to discuss use cases such as HPC, Broadcast & Media, Big Data, Finance and Storage, as well as data centre innovation and co-location. “We provide full application stacks for a range of verticals as well as on-demand consultancy from our expert team,” said David Power, vScaler CTO. “Our tailor-made, software-defined infrastructure cuts away time wasted on the distractions of setup and enables our users to concentrate on the task at hand.”
IBM Adds TensorFlow Support for PowerAI Deep Learning
Today IBM announced that its PowerAI distribution for popular open source Machine Learning and Deep Learning frameworks on the POWER8 architecture now supports the TensorFlow 0.12 framework that was originally created by Google. TensorFlow support through IBM PowerAI provides enterprises with another option for fast, flexible, and production-ready tools and support for developing advanced machine learning products and systems.
New AMD Radeon Instinct Rolls Out to Accelerate Machine Intelligence

“New Radeon Instinct accelerators will offer organizations powerful GPU-based solutions for deep learning inference and training. Along with the new hardware offerings, AMD announced MIOpen, a free, open-source library for GPU accelerators intended to enable high-performance machine intelligence implementations, and new, optimized deep learning frameworks on AMD’s ROCm software to build the foundation of the next evolution of machine intelligence workloads.”
HIP and CAFFE Porting and Profiling with AMD’s ROCm

In this video from SC16, Ben Sander from AMD presents: HIP and CAFFE Porting and Profiling with AMD’s ROCm. “We are excited to present ROCm, the first open-source HPC/Hyperscale-class platform for GPU computing that’s also programming-language independent. We are bringing the UNIX philosophy of choice, minimalism and modular software development to GPU computing. The new ROCm foundation lets you choose or even develop tools and a language run time for your application. ROCm is built for scale; it supports multi-GPU computing in and out of server-node communication through RDMA.”
New Bright for Deep Learning Solution Designed for Business
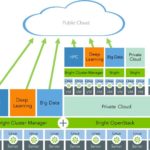
“We have enhanced Bright Cluster Manager 7.3 so our customers can quickly and easily deploy new deep learning techniques to create predictive applications for fraud detection, demand forecasting, click prediction, and other data-intensive analyses,” said Martijn de Vries, Chief Technology Officer of Bright Computing. “Going forward, customers using Bright to deploy and manage clusters for deep learning will not have to worry about finding, configuring, and deploying all of the dependent software components needed to run deep learning libraries and frameworks.”
Machine Learning and the Intel Xeon Phi Processor
“With up to 72 processing cores, the Intel Xeon Phi processor x200 can accelerate applications tremendously. Each core contains two Advanced Vector Extensions, which speeds up the floating point performance. This is important for machine learning applications which in many cases use the Fused Multiply-Add (FMA) instruction.”
Fujitsu Develops High-Speed Software for Deep Learning
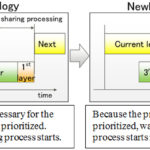
“Fujitsu Laboratories has newly developed parallelization technology to efficiently share data between machines, and applied it to Caffe, an open source deep learning framework widely used around the world. Fujitsu Laboratories evaluated the technology on AlexNet, where it was confirmed to have achieved learning speeds with 16 and 64 GPUs that are 14.7 and 27 times faster, respectively, than a single GPU. These are the world’s fastest processing speeds(2), representing an improvement in learning speeds of 46% for 16 GPUs and 71% for 64 GPUs.”
