
This new GigaOm Radar Report provided by our friends over at Vertica, examines the leading platforms in the data warehouse marketplace, describes the fundamentals of the technology, identifies key criteria and evaluation metrics by which organizations can evaluate competing platforms, describes some potential technology developments to look out for in the future, and classifies platforms across those criteria and metrics.
Univa Grid Engine Powers University of Oxford Human Genetics Centre
November 24, 2017 by

Last week at SC17, Univa announced its Univa Grid Engine distributed resource management system is powering the Wellcome Centre for Human Genetics’ (WHG) high performance computing environment. WHG is a research institute within the Nuffield Department of Medicine at the University of Oxford. The Centre is an international leader in genetics, genomics, statistics and structural biology with more than 400 researchers and 70 administrative and support personnel. WHG’s mission is to advance the understanding of genetically-related conditions through a broad range of multi-disciplinary research.
Designing HPC, Big Data, & Deep Learning Middleware for Exascale
October 31, 2017 by

DK Panda from Ohio State University presented this talk at the HPC Advisory Council Spain Conference. “This talk will focus on challenges in designing HPC, Big Data, and Deep Learning middleware for Exascale systems with millions of processors and accelerators. For the HPC domain, we will discuss about the challenges in designing runtime environments for MPI+X (PGAS OpenSHMEM/UPC/CAF/UPC++, OpenMP, and CUDA) programming models. Features and sample performance numbers from MVAPICH2 libraries will be presented.”
NEC Vector Computers Accelerate Machine Learning
July 3, 2017 by

Today NEC Corporation announced that it has developed new Aurora Vector Engine data processing technology that accelerates the execution of machine learning on vector computers by more than 50 times in comparison to Spark technologies. “This technology enables users to quickly benefit from the results of machine learning, including the optimized placement of web advertisements, recommendations, and document analysis,” said Yuichi Nakamura, General Manager, System Platform Research Laboratories, NEC Corporation. “Furthermore, low-cost analysis using a small number of servers enables a wide range of users to take advantage of large-scale data analysis that was formerly only available to large companies.”
Bringing HPC Algorithms to Big Data Platforms
March 1, 2017 by

Nikolay Malitsky from Brookhaven National Laboratory presented this talk at the Spark Summit East conference. “This talk will present a MPI-based extension of the Spark platform developed in the context of light source facilities. The background and rationale of this extension are described in the paper “Bringing the HPC reconstruction algorithms to Big Data platforms.” which highlighted a gap between two modern driving forces of the scientific discovery process: HPC and Big Data technologies. As a result, it proposed to extend the Spark platform with inter-worker communication for supporting scientific-oriented parallel applications.”
Intel DAAL Accelerates Data Analytics and Machine Learning
February 23, 2017 by

Intel DAAL is a high-performance library specifically optimized for big data analysis on the latest Intel platforms, including Intel Xeon®, and Intel Xeon Phi™. It provides the algorithmic building blocks for all stages in data analysis in offline, batch, streaming, and distributed processing environments. It was designed for efficient use over all the popular data platforms and APIs in use today, including MPI, Hadoop, Spark, R, MATLAB, Python, C++, and Java.
New Bright for Deep Learning Solution Designed for Business
September 1, 2016 by
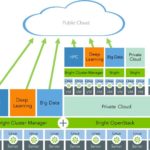
“We have enhanced Bright Cluster Manager 7.3 so our customers can quickly and easily deploy new deep learning techniques to create predictive applications for fraud detection, demand forecasting, click prediction, and other data-intensive analyses,” said Martijn de Vries, Chief Technology Officer of Bright Computing. “Going forward, customers using Bright to deploy and manage clusters for deep learning will not have to worry about finding, configuring, and deploying all of the dependent software components needed to run deep learning libraries and frameworks.”
NERSC to Host Data Day on August 22
July 26, 2016 by

Today NERSC announced plans to host a new, data-centric event called Data Day. The main event will take place on August 22, followed by a half-day hackathon on August 23. The goal: to bring together researchers who use, or are interested in using, NERSC systems for data-intensive work.
Video: Exploiting HPC Technologies to Accelerate Big Data Processing
April 15, 2016 by

“This talk will present RDMA-based designs using OpenFabrics Verbs and heterogeneous storage architectures to accelerate multiple components of Hadoop (HDFS, MapReduce, RPC, and HBase), Spark and Memcached. An overview of the associated RDMAenabled software libraries being designed and publicly distributed as a part of the HiBD project.”
Interview: How Univa Short Jobs Brings Low Latency to Financial Services
June 22, 2015 by

With the launch of Univa Small Jobs add-on for Univa Grid Engine, the company, the company offers “the world’s most efficient processing and lowest latency available for important tasks like real-time trading, transactions, and other critical applications.” To learn more, we caught up with Univa President & CEO Gary Tyreman.

