
A news story in the Korean news publication Pulse reported today that Samsung electronics has confirmed “a new order for 3-nanometer high performance server chips.” The Pulse story stated that semiconductor designer ADTechnology Co., a Korea-based design solution partner of Samsung and member of the AADP (Arm Approved….
Report: Samsung Secures Order for 3nm Server Chips for US Company ‘Involved in HPC’
October 11, 2023 by
HPC, AI, ML and Edge Solutions Drive Duos Railcar Inspection System Powered by Dell Technologies and Kalray
October 2, 2023 by
Industries such as railways are moving from traditional inspection methods to using AI and ML to perform automated inspection of….
Arm Introduces Neoverse Compute Subsystems
August 28, 2023 by
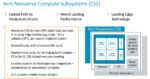
At Hot Chips today, Arm introduced the Arm Neoverse Compute Subsystems (CSS) designed to enable Arm users to build specialized silicon at lower cost, with less risk and faster time-to-market compared to discrete IP. Available today, Arm CSS N2 is a pre-integrated, PPA-optimized configuration of the Neoverse N2….
Gartner Reports Composable Infrastructure Increases Market Penetration up to 10x
August 25, 2023 by

August 24, 2023 – Technology industry analyst firm Gartner has issued four new “Hype Cycle” reports for 2023 in which composable infrastructure is given a “high” benefit” rating, according to an announcement from composable infrastructure company GigaIO. While acknowledging barriers to adoption….
@HPCpodcast: Evaluating Specialty AI Chips at Argonne’s AI Testbed
August 21, 2023 by
Our latest episode of @HPCpodcast delves into the Cambrian explosion of AI specialty chips – of which there so many have been released on the HPC-AI market that it’s hard to discern which chip is right for what workload. Hence the AI Testbed at the Argonne Leadership Computing Facility. Shahin and Doug spoke with Venkat Vishwanath….
HPC News Bytes 20230821: Intel Ends Tower Bid; Hot Chips Conference; GPU Demand; Samsung’s Texas 4nm Fab
August 21, 2023 by

Good Monday morning! Here’s a quick summation of recent HPC news: Intel kills Tower Semi deal; Hot Chips preview; GPU shortage as generative AI heats up; Samsung’s Texas 4nm chip fab….
Cornelis Partners with Penguin and Panasas on New HPC-AI Reference Design
August 15, 2023 by
WAYNE, PA. — August 22, 2023 – Cornelis Networks, a provider of high-performance networking solutions for data-intensive technical computing (HPC and AI) applications, today announced a partnership with Penguin Solutions, a provider of HPC, AI, and IoT technologies and services; and Panasas, a provider of HPC and AI storage solutions. The three companies have come together to define and […]
NVIDIA at SIGGRAPH: DGX Integration with Hugging Face for LLM Training; Announcement of AI Workbench
August 8, 2023 by

At the the SIGGRAPH conference this morning in Los Angeles, NVIDIA made several generative AI-related announcements, including a partnership with Hugging Face intended to broaden access to generative AI supercomputing (NVIDIA’s DGX cloud hardware) for developers building large language models (LLMs) and other AI applications on the Hugging Face platform. The companies said the combination […]
HPC and AI Workloads Drive Storage System Design
August 7, 2023 by
Many organizations are tied to outdated storage systems that cannot meet HPC and AI workload needs. Designing high‑throughput, highly scalable HPC storage systems require expert planning and configuration. The Dell Validated Designs for HPC Storage solution offers a way to quickly upgrade antiquated storage….
McKinsey on the Future of Compute: The Rise of Domain-Specific Architectures
August 2, 2023 by

There’s more to the rise in HPC and AI of domain-specific architectures (DSAs), starting with GPUs, than just the superior throughput they can deliver. Yes, the deceleration of Moore’s Law and Dennard scaling are the primary reasons for the CPU’s decline in dominance. But other factors are playing a strong, enabling role for DSAs. Consulting […]

