The Argonne Leadership Computing Facility (ALCF), together with NVIDIA and OpenACC, is co-organizing a hybrid hackathon to help research teams prepare for the upcoming 2024 INCITE call for proposals. Hackathon dates: April 18: Team/Mentor virtual meeting from 09:00 – 11:00 AM CT April 25: Virtual meeting 9:00 AM – 5:00 PM May 3-5: The event […]
OpenACC and Hackathons Summit 2022 Aug. 2-4
July 8, 2022 by
July 8, 2022 — OpenACC will hold its annual summit from Tuesday, Aug. 2 to Thursday, Aug. 4, 2022 from 7-11 am Pacific Time. It will be a digital event. The event website is here. OpenACC said this annual summit showcases leading research both accelerated by the OpenACC directives-based programming model and optimized through the […]
Clacc – Open Source OpenACC Compiler and Source Code Translation Project
March 16, 2021 by
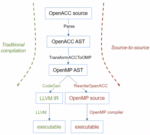
By Rob Farber, contributing writer for the Exascale Computing Project Clacc is a Software Technology development effort funded by the US Exascale Computing Project (ECP) PROTEAS-TUNE project to develop production OpenACC compiler support for Clang and the LLVM Compiler Infrastructure Project (LLVM). The Clacc project page notes, “OpenACC support in Clang and LLVM will facilitate the programming of GPUs and other accelerators in DOE applications, […]
OpenACC Names ORNL’s Jack Wells President, Updates OpenACC API
November 24, 2020 by
Jack Wells, director of strategic planning and performance management at Oak Ridge National Laboratory, has been named president of OpenACC, a nonprofit dedicated to advancing scientists’ parallel computing skills. OpenACC also announced updates to Version 3.1 of OpenACC API for writing parallel programs in C, C++, and Fortran, and it announced the 2021 schedule of […]
EPEEC Project Fosters Heterogeneous HPC Programming in Europe
April 13, 2020 by

The European Programming Environment for Programming Productivity of Heterogeneous Supercomputers (EPEEC) is a project that aims to combine European made tools for programming models and performance tools that could help to relieve the burden of targeting highly-heterogeneous supercomputers. It is hoped that this project will make researchers jobs easier as they can more effectively use large scale HPC systems.
Building Cloud-Based Services to Enable Earth Science Workflows across HPC Centres
March 6, 2020 by

In this video from FOSDEM 2020, John Hanley from ECMWF presents: Building Cloud-Based Services to Enable Earth Science Workflows across HPC Centres. Weather forecasts produced by ECMWF and environment services by the Copernicus programme act as a vital input for many downstream simulations and applications. A variety of products, such as ECMWF reanalyses and archived […]
Video: Jack Wells from ORNL on his new role as VP of OpenACC.org
June 16, 2019 by

Today OpenACC.org announced a newly elected vice president reflecting increased user influence within the organization. Additionally, the organization announced its 2019 Annual Meeting will be hosted by RIKEN Center for Computational Science (RIKEN R-CCS) in Japan, as well as the schedule of upcoming hackathons and bootcamps around the world.
Video: Speeding up Programs with OpenACC in GCC
February 11, 2019 by

Thomas Schwinge from Mentor gave this talk at FOSDEM’19. “Requiring only few changes to your existing source code, OpenACC allows for easy parallelization and code offloading to accelerators such as GPUs. We will present a short introduction of GCC and OpenACC, implementation status, examples, and performance results.”
Call For Proposals: Worldwide GPU Hackathons in 2019
January 23, 2019 by

ORNL has issued its Call for Proposals for a set of global GPU Hackathons in 2019. “A GPU hackathon is a 5-day coding event in which teams of developers port their applications to run on GPUs, or optimize their applications that already run on GPUs. Each team consists of three or more developers who are intimately familiar with (some part of) their application, and they work alongside two mentors with GPU programming expertise. The mentors come from universities, national laboratories, supercomputing centers, government institutions, and vendors.”
Video: How OpenACC Enables Scientists to port their codes to GPUs and Beyond
December 9, 2018 by

In this video SC18, Jack Wells from ORNL describes how OpenACC enables scientists to port their codes to GPUs and other HPC platforms. “OpenACC, a directive-based high-level parallel programming model, has gained rapid momentum among scientific application users – the key drivers of the specification. The user-friendly programming model has facilitated acceleration of over 130 applications including CAM, ANSYS Fluent, Gaussian, VASP, Synopsys on multiple platforms and is also seen as an entry-level programming model for the top supercomputers (Top500 list) such as Summit, Sunway Taihulight, and Piz Daint. As in previous years, this BoF invites scientists, programmers, and researchers to discuss their experiences in adopting OpenACC for scientific applications, learn about the roadmaps from implementers and the latest developments in the specification.”
