
Today ORNL announced the full schedule of 2017 GPU Hackathons at multiple locations around the world. “The goal of each hackathon is for current or prospective user groups of large hybrid CPU-GPU systems to send teams of at least 3 developers along with either (1) a (potentially) scalable application that could benefit from GPU accelerators, or (2) an application running on accelerators that need optimization. There will be intensive mentoring during this 5-day hands-on workshop, with the goal that the teams leave with applications running on GPUs, or at least with a clear roadmap of how to get there.”
Parallware: LLVM-Based Tool for Guided Parallelization with OpenMP
December 19, 2016 by

Manuel Arenaz from Appentra presented this talk at the OpenMP booth at SC16. “Parallware is a new technology for static analysis of programs based on the production-grade LLVM compiler infrastructure. Using a fast, extensible hierarchical classification scheme to address dependence analysis, it discovers parallelism and annotates the source code with the most appropriate OpenMP & OpenACC directives.”
Appentra Solutions will be part of SC16 Emerging Technologies Showcase
November 11, 2016 by

Today Appentra Solutions announced that the company will participate in the Emerging Technologies Showcase at SC16. As an HPC startup, Appentra was selected for its Parallware technology, an LLVM-based software technology that assists in the parallelization of scientific codes with OpenMP and OpenACC. “The new Parallware Trainer is a great tool for providing support to parallel programmers on their daily work,” said Xavier Martorell, Parallel Programming Models Group Manager at Barcelona Supercomputing Center.
PSyclone Software Eases Weather and Climate Forecasting
September 21, 2016 by

“PSyclone was developed for the UK Met Office and is now a part of the build system for Dynamo, the dynamical core currently in development for the Met Office’s ‘next generation’ weather and climate model software. By generating the complex code needed to make use of thousands of processors, PSyclone leaves the Met Office scientists free to concentrate on the science aspects of the model. This means that they will not have to change their code from something that works on a single processing unit (or core) to something that runs on many thousands of cores.”
NERSC Dungeon Session Speeds Code for Cori Supercomputer
August 20, 2016 by
Six application development teams from NERSC gathered at Intel in early August for a marathon “dungeon session” designed to help tweak their codes for the next-generation Intel Xeon Phi Knight’s Landing manycore architecture and NERSC’s new Cori supercomputer. “We try to prepare ahead of time to bring the types of problems that can only be solved with the experts at Intel and Cray present—deep questions about the architecture and how applications use the Xeon Phi processor. It’s all geared toward optimizing the codes to run on the new manycore architecture and on Cori.”
Inria Joins OpenMP ARB
July 25, 2016 by

“Inria teams have been developing runtime systems and compiler techniques for parallel programming over several decades.” says Olivier Aumage, researcher at Inria’s team STORM, “By joining the OpenMP ARB today, Inria looks forward to contribute this expertise in making OpenMP meet the challenges of the Exascale era”.
Video: Speeding Up Code with the Intel Distribution for Python
June 11, 2016 by
David Bolton from Slashdot shows how ‘embarrassingly parallel’ code can be sped up over 2000x (not percent) by utilizing Intel tools including the Intel Python compiler and OpenMP. “The Intel Distribution for Python* 2017 Beta program is now available. The Beta product adds new Python packages like scikit-learn, mpi4py, numba, conda, tbb (Python interfaces to Intel Threading Building Blocks) and pyDAAL (Python interfaces to Intel Data Analytics Acceleration Library). “
Video: UPC++ Parallel Programming Extension
April 20, 2016 by
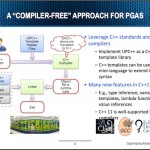
In this video from the 2016 OpenFabrics Workshop, Zili Zheng from LBNL presents: UPC++. “UPC++ is a parallel programming extension for developing C++ applications with the partitioned global address space (PGAS) model. UPC++ has demonstrated excellent performance and scalability with applications and benchmarks such as global seismic tomography, Hartree-Fock, BoxLib AMR framework and more. In this talk, we will give an overview of UPC++ and discuss the opportunities and challenges of leveraging modern network features.”
Application Performance & Power Consumption on Intel Xeon Phi
April 7, 2016 by
“While new technology will be developed that reduces the power per operation needed, in today’s environments it is important to understand how an application affects power usage. For modern applications that have been optimized to take advantage of both the Intel Xeon CPU and the Intel Xeon Phi coprocessor, the hardware mentioned does include various power states, which can minimize the power consumption when idle.”
FlyElephant Platform Adds Private Repositories
March 15, 2016 by

flyelephantToday the FlyElephant announced a number of upgrades that allow users to work with private repositories with an improved system security and good task functionality. “FlyElephant is a platform for scientists, providing a computing infrastructure for calculations, helping to find partners for the collaboration on projects, and managing all data from one place. FlyElephant automates routine tasks and helps to focus on core research issues.”

