Overarching both themes is the slowing of Moore’s Law, the deceleration of improvement in HPC performance combined with increasing costs for new generations of systems. In addition, implementing and realizing the benefits of new systems is slowing as supercomputers grow in size and complexity, including those handling AI, AI for science, traditional HPC simulation ….
INCITE Proposal Writing Webinar May 7
May 2, 2024 by Leave a Comment
May 2, 2024 — The Department of Energy’s Innovative and Novel Computational Impact on Theory and Experiment (INCITE) program is the principal means for the scientific community gains access to DOE’s leadership-class supercomputers at the Argonne Leadership Computing Facility and Oak Ridge Leadership Computing Facility. The next INCITE Proposal Writing Webinar will take place on May […]
Durham University Cosmologists, DiRAC and Dell Improve HPC Energy Efficiency without Sacrificing Performance
May 1, 2024 by Leave a Comment
[SPONSORED GUEST ARTICLE] Since the beginning of human existence, people have looked into the night sky and wondered how the universe began. Cosmologists using the UK’s Memory Intensive DiRAC HPC service at Durham ….
HPE Launches 35 Pflops ‘Helios’ HPC at Centre Cyfronet AGH in Poland
April 30, 2024 by Leave a Comment

KRAKOW, Poland – Hewlett Packard Enterprise (NYSE: HPE) announced that it built a new supercomputer for the Academic Computer Centre Cyfronet of the AGH University of Krakow, making it Poland’s fastest system based on the latest TOP500 list of the world’s most powerful supercomputers1. The new system, called Helios, is Cyfronet’s fifth-generation supercomputer and will be […]
JetCool Unveils Liquid Cooling for Nvidia H100 GPUs
April 30, 2024 by Leave a Comment
Littleton MA – April 30, 2024 – Liquid cooling company JetCool today announced the availability of its liquid cooling module for Nvidia’s H100 SXM and PCIe GPUs. Unveiled initially at the 2023 Supercomputing Conference, JetCool’s SmartPlate technology has undergone extensive performance validation with Nvidia’s H100 GPUs. It surpasses conventional air cooling methods, delivering a performance improvement […]
DOE Annunces Actions in Support of White House AI Executive Orders
April 29, 2024 by Leave a Comment

WASHINGTON, D.C. — The U.S. Department of Energy (DOE) today announced a series of actions in support of the Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. DOE issued AI and Energy: Opportunities for a Modern Grid and Clean Energy Economy, which is a first-ever report on AI’s near-term potential […]
Intersect360 Sizes HPC-AI Market at $85.7B, Up 62% Driven by Hyperscalers
April 29, 2024 by Leave a Comment
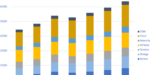
Analyst firm Intersect360 Research has released its annual report placing the worldwide market for scalable computing infrastructure for HPC and AI at $85.7 billion in 2023, up 62.4 percent year-over-year. This was mainly due to a near tripling of spending by ….
HPC News Bytes 20240429: Exorbitant AI Infra-Tech, Advanced Chips in China, Neuromorphic HPC, an AI Bubble?
April 29, 2024 by Leave a Comment

A good mid-spring morn to you! You’re invited to join Shahin and Doug on a jaunt (6:04) through recent HPC-AI developments, including: AI infra-tech’s booming costs and data center scarcity problems, a possibe AI bubble ….
IBM in $137M Semiconductor Agreement with Canada
April 26, 2024 by Leave a Comment
BROMONT, QC, April 26, 2024 — IBM, the government of Canada and the government of Quebec today announced agreements to develop the assembly, testing and packaging (ATP) capabilities for semiconductor modules for telecommunications, high performance computing (HPC), automotive, aerospace and defence, computer networks and generative AI, at IBM Canada’s plant in Bromont, Quebec. The agreements reflect […]
Nvidia AI Enterprise Available on Oracle US Government Cloud
April 25, 2024 by Leave a Comment

April 25, 2024 — Oracle today announced that Nvidia AI Enterprise on Oracle Cloud Infrastructure Supercluster is now available in the Oracle U.S. Government Cloud region to help address sovereign AI. Building on the expansion of their partnership, Oracle and Nvidia are helping U.S. government customers train and deploy AI solutions with access to Oracle Cloud Infrastructure’s 100+ services, […]

