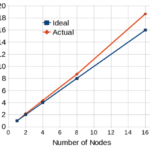
The HiFUN CFD solver shows that the latest-generation Intel Xeon Scalable processor enhances single-node performance due to the availability of large cache, higher core density per CPU, higher memory speed, and larger memory bandwidth. The higher core density improves intra-node parallel performance that permits users to build more compact clusters for a given number of processor cores. This permits the HiFUN solver to exploit better cache utilization that contributes to super-linear performance gained through the combination of a high-performance interconnect between nodes and the highly-optimized Intel® MPI Library.
Maximizing Performance of HiFUN* CFD Solver on Intel® Xeon® Scalable Processor With Intel MPI Library
June 12, 2018 by
Data Compression Optimized with Intel® Integrated Performance Primitives
May 21, 2018 by

Intel® Integrated Performance Primitives (Intel IPP) offers the developer a highly optimized, production-ready, library for lossless data compression/decompression that targets image, signal, and data processing, and cryptography applications. The Intel IPP optimized implementations of the common data compression algorithms are “drop-in” replacements for the original compression code.
High Performance Big Data Computing Using Harp-DAAL
May 15, 2018 by

Harp-DAAL is a framework developed at Indiana University that brings together the capabilities of big data (Hadoop) and techniques that have previously been adopted for high performance computing. Together, employees can become more productive and gain deeper insights to massive amounts of data.
Python Can Do It
April 9, 2018 by
“Python remains a single threaded environment with the global interpreter lock as the main bottleneck. Threads must wait for other threads to complete before starting to do their assigned work. The result of this model is that production code is produced that is too slow to be useful for large simulations.”
Intel AVX Gives Numerical Computations in Java a Big Boost
March 22, 2018 by

Recent Intel® enhancements to Java enable faster and better numerical computing. In particular, the Java Virtual Machine (JVM) now uses the Fused Multiply Add (FMA) instructions on Intel Intel Xeon® PhiTM processors with Advanced Vector Instructions (Intel AVX) to implement the Open JDK9 Math.fma()API. This gives significant performance improvements for matrix multiplications, the most basic computation found in most HPC, Machine Learning, and AI applications.
FPGA Programming Made Easy
March 15, 2018 by

In the past, it was necessary to understand a complex programming language such as Verilog or VHDL, that was designed for a specific FPGA. “Using a familiar language such as OpenCL, developers can become more productive, sooner when deciding to use an FPGA for a specific purpose. OpenCL is portable and is designed to be used with almost any type of accelerator.”
Intel MKL Speeds Up Automated Driving Workloads on the Intel Xeon Processor
March 8, 2018 by
The automated driving developer community typically uses Eigen*, a C++ math library, for the matrix operations required by the Extended Kalman Filter algorithm. EKF usually involves many small matrices. However most HPC library routines for matrix operations are optimized for large matrices. “Intel MKL provides highly-tuned xGEMM function for matrix-matrix multiplication, with special paths for small matrices. Eigen can take advantage of Intel MKL through use of a compiler flag. A significant speedup results when using Eigen and Intel MKL and compiling the automated driving apps with the latest Intel C++ compiler.”
Performance Insights Using the Intel Advisor Python API
March 1, 2018 by

Tuning a complex application for today’s heterogeneous platforms requires an understanding of the application itself as well as familiarity with tools that are available for assisting with analyzing where in the code itself to look for bottlenecks. The process for optimizing the performance of an application, in general, requires the following steps that are most likely applicable for a wide range of applications.
Intel MKL Compact Matrix Functions Attain Significant Speedups
February 22, 2018 by
The latest version of Intel® Math Kernel Library (MKL) offers vectorized compact functions for general and specialized matrix computations of this type. These functions rely on true SIMD (single instruction, multiple data) matrix computations, and provide significant performance benefits compared to traditional techniques that exploit multithreading but rely on standard data formats.
Flow Graph Analyzer – Speed Up Your Applications
February 15, 2018 by

Using the Intel® Advisor Flow Graph Analyzer (FGA), an application such as those that are needed for autonomous driving can be developed and implemented using very high performing underlying software and hardware. Under the Intel FGA, are the Intel Threaded Building Blocks which take advantage of the multiple cores that are available on all types of systems today.

