
In this special guest feature, Tim Miller, Braden Cooper, Product Marketing Manager at One Stop Systems (OSS), suggests that for AI inferencing platforms, the data must be processed in real time to make the split-second decisions that are required to maximize effectiveness. Without compromising the size of the data set, the best way to scale the model training speed is to add modular data processing nodes.
Search Results for: scalability
Intel Horse Ridge Chip Addresses Key Barriers to Quantum Scalability
February 19, 2020 by

At the International Solid-State Circuits Conference this week, Intel presented a research paper demonstrating the technical details and experimental results of its new Horse Ridge cryogenic quantum computing control chip. “Building fault-tolerant, commercial-scale quantum computers requires a scalable architecture for both qubits and control electronics. Horse Ridge is a highly integrated System-on-a-Chip (SoC) that provides an elegant solution to enable control of multiple qubits with high fidelity—a major milestone on the path to quantum practicality.”
GigaIO Optimizes Scalability of Xilinx Alveo FPGAs
October 4, 2019 by
Today GigaIO introduced FabreX support for Xilinx Alveo Accelerators, in addition to an exclusive offering that provides Xilinx FPGA developers with remote cloud access to the FabreX platform. In conjunction with the Xilinx Alveo family of adaptable accelerator cards, Xilinx developers will use FabreX to enhance proof of concept, software testing, and scale-out deployments in applications like artificial intelligence, deep learning inference, and high-performance computing.
Offering Bare-Metal Performance and Scalability on Cloud: The Azure-HPC Approach
September 2, 2019 by

Jithin Jose from Microsoft gave this talk at the MVAPICH User Group. “This talk focuses on how HPC offerings in Azure address these challenges and explains the design pillars that allow Microsoft to offer “bare-metal performance and scalability” on the Microsoft Azure Cloud. This talk also covers the features of latest Microsoft Azure HPC offerings and provides in-depth performance insights and recommendations for using MVAPICH2 and MVAPICH2-X on Microsoft Azure.”
Improving Speed, Scalability and the Customer Experience with In-Memory Data Grids
August 14, 2018 by Leave a Comment

Over the last decade, the new anytime, anywhere, personalized experience has driven query and transaction volumes up 10 to 1000x. It has created 50x more data about customers, products, and interactions. It has also shrunk the response times customers expect from days or hours to seconds or less. Download the new report from GridGain to learn how in-memory computing and in-memory data grids are tackling today’s data storage challenges.
Improving Deep Learning scalability on HPE servers with NovuMind: GPU RDMA made easy
June 13, 2018 by

Bruno Monnet from HPE gave this talk at the NVIDIA GPU Technology Conference. “Deep Learning demands massive amounts of computational power. Those computation power usually involve heterogeneous computation resources, e.g., GPUs and InfiniBand as installed on HPE Apollo. NovuForce deep learning softwares within the docker image has been optimized for the latest technology like NVIDIA Pascal GPU and infiniband GPUDirect RDMA. This flexibility of the software, combined with the broad GPU servers in HPE portfolio, makes one of the most efficient and scalable solutions.”
GridGain In-Memory Computing Platform Delivers Speed and Scalability
June 4, 2018 by
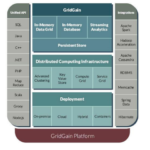
The GridGain In-Memory computing platform works to deliver speed and scalability for your large data needs. The platform is built on the Apache Ignite open source project. Download the new white paper today, “Introducing the GridGain In-Memory Computing Platform,” to find out if GridGain is the right choice for you.
Highest Peformance and Scalability for HPC and AI
February 23, 2018 by

Scot Schultz from Mellanox gave this talk at the Stanford HPC Conference. “Today, many agree that the next wave of disruptive technology blurring the lines between the digital, physical and even the biological, will be the fourth industrial revolution of AI. The fusion of state-of-the-art computational capabilities, extensive automation and extreme connectivity is already affecting nearly every aspect of society, driving global economics and extending into every aspect of our daily life.”
Reliability, Scalability and Performance – the Impact of Intel HPC Orchestrator
May 23, 2017 by

When it comes to getting the performance out of your HPC system, it’s the small things that count. David Lombard, Sr. Principal Engineer at Intel Corporation, explains. ” Intel HPC Orchestrator encapsulates the important tradeoffs, and pays attention to the small details that can greatly impact how well the underlying features of the hardware are leveraged to deliver better performance and scalability.”
Call for Papers: Workshop On Performance and Scalability of Storage Systems (WOPSSS)
February 28, 2017 by

The Second Workshop On Performance and Scalability of Storage Systems (WOPSSS) has issued its Call for Papers. The one-day workshop will be held jointly with ISC 2017 in Frankfurt, Germany. “The Workshop On Performance and Scalability of Storage Systems aims to present state-of-the-art research, innovative ideas, and experience that focus on the design and implementation of HPC storage systems in both academic and industrial worlds, with a special interest on their performance analysis. The arrival of new storage technologies and scales unseen in previous practice lead to significant loss of performance predictability. This will leave storage system designers, application developers and the storage community at large in the difficult situation of not being able to precisely detect bottlenecks, evaluate the room for improvement, or estimate the matching of applications with a given storage architecture.”

