
A happy August Monday morning to you. It was an interesting week for supercomputing news, and Shahin and Doug share the highlights of recent developments: Linux Wars continue: Oracle, SUSE, and CIQ form Open Enterprise Linux Association (watch for upcoming episodes on @HPCpodcast on this); China’s tech companies place $5 billion of orders on US chips; Intel improves hardware for on-chip AVX (or APX) vector instructions; 2023 Gordon Bell Prize Finalists also point to TOP500
HPC News Bytes 20230814: Linux Wars, China and Chips, Intel AVX, Gordon Bell Prize Finalists
August 14, 2023 by
ExaWorks: Tested Component for HPC Workflows
July 27, 2023 by
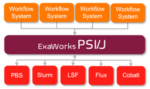
ExaWorks is an Exascale Computing Project (ECP)–funded project that provides access to hardened and tested workflow components through a software development kit (SDK). Developers use this SDK and associated APIs to build and deploy production-grade, exascale-capable workflows on US Department of Energy (DOE) and other computers. The prestigious Gordon Bell Prize competition highlighted the success of the ExaWorks SDK when the Gordewinner and two of three finalists in the 2020 Association for Computing Machinery (ACM) Gordon Bell Special Prize for High Performance Computing–Based COVID-19 Research competition leveraged ExaWorks technologies.
At SC22: ACM Gordon Bell Prize Awarded for Particle-In-Cell Simulations on Frontier, Fugaku, Summit and Perlmutter Supercomputers
November 17, 2022 by

New York, NY, November 17, 2022 – ACM, the Association for Computing Machinery, named a 16-member team drawn from French, Japanese, and US institutions as recipient of the 2022 ACM Gordon Bell Prize for their project, “Pushing the Frontier in the Design of Laser-Based Electron Accelerators With Groundbreaking Mesh-Refined Particle-In-Cell Simulations on Exascale-Class Supercomputers.” The members of […]
Research Team Uses Summit to Earn Gordon Bell Prize Nomination for Simulating Carbon in Extreme Conditions
November 17, 2021 by
A research team used machine-learned descriptions of interatomic interactions on the 200-petaflop Summit supercomputer at the US Department of Energy’s (DOE’s) Oak Ridge National Laboratory (ORNL) to model more than a billion carbon atoms at quantum accuracy and observe how diamonds behave under some of the most extreme pressures and temperatures imaginable. The team was led by scientists […]
ORNL Study on COVID-19 Earns Gordon Bell Prize Nomination
November 16, 2021 by
As the coronavirus pandemic entered its second year, a team of scientists from the U.S. Department of Energy’s Oak Ridge National Laboratory used the nation’s fastest supercomputer to streamline the search for potential treatments. “The approach we used to search for promising molecules resembles natural selection in fast forward,” said Andrew Blanchard, one of the […]
Winners of Student Cluster Competition, Gordon Bell Prize(s) Named at SC20
November 19, 2020 by

It was awards day at Virtual SC20, and among the most coveted and closely watched of them ate annual SC Student Cluster Competition and the ACM Gordon Bell Prize. This year’s cluster competition winner: Tsinghaua University, China. The same team won the competition for the highest LINPACK benchmark performance. Now in its 14th year, this […]
New Gordon Bell Special Prize announced for HPC-Based COVID-19 Research
May 12, 2020 by

Today ACM announced the inception of the ACM Gordon Bell Special Prize for HPC-Based COVID-19 Research. The new award will be presented in 2020 and 2021 and will recognize outstanding research achievements that use high performance computing applications to understand the COVID-19 pandemic, including the understanding of its spread. Nominations will be selected based on performance and innovation in their computational methods, in addition to their contributions toward understanding the nature, spread and/or treatment of the disease.
A Data-Centric Approach to Extreme-Scale Ab initio Dissipative Quantum Transport Simulations
May 7, 2020 by

Alexandros Ziogas from ETH Zurich gave this talk at Supercomputing Frontiers Europe. “The computational efficiency of a state of the art ab initio #quantum transport (QT) solver, capable of revealing the coupled electro-thermal properties of atomically-resolved nano-transistors, has been improved by up to two orders of magnitude through a data centric reorganization of the application. The approach yields coarse-and fine-grained data-movement characteristics that can be used for performance and communication modeling, communication-avoidance, and dataflow transformations.”
Data-centric Programming Helps ETH Zurich Team Win Gordon Bell Prize
November 22, 2019 by

Today ACM named a six-member team from ETH Zurich recipients of the 2019 ACM Gordon Bell Prize for their work on DaCe OMEN, a new framework for simulating the transport of electrical signals through nanoscale materials. “The ETH Zurich researchers simulated the 10,000-atom system 14 times faster than an earlier framework that was used for a 1,000- atom system. The DaCe OMEN code they developed for the simulation has been run on two top-6 hybrid supercomputers, reaching a sustained performance of 85.45 Pflop/s on 4,560 nodes of Summit (42.55% of the peak) in double precision, and 90.89 Pflop/s in mixed precision.”
Supercomputing Takes on the Opioid Crisis
May 30, 2019 by

In this special guest feature from the SC19 Blog, Dan Jacobson and Wayne Joubert from ORNL describes how the Summit supercomputer is helping untangle how genetic variants, gleaned from vast datasets, can impact whether an individual is susceptible (or not) to disease, including chronic pain and opioid addiction.

