insideHPC in association with the technology analyst firm OrionX.net today announced the launch of the @HPCpodcast, featuring OrionX.net analyst Shahin Khan and Doug Black, insideHPC’s editor-in-chief. @HPCpodcast is intended to be a lively and informative forum examining key technology trends driving high performance computing and artificial intelligence. Each podcast will feature Khan and Blacks’ comments […]
HPC: Stop Scaling the Hard Way
October 12, 2021 by
…today’s situation is clear: HPC is struggling with reliability at scale. Well over 10 years ago, Google proved that commodity hardware was both cheaper and more effective for hyperscale processing when controlled by software-defined systems, yet the HPC market persists with its old-school, hardware-based paradigm. Perhaps this is due to prevailing industry momentum or working within the collective comfort zone of established practices. Either way, hardware-centric approaches to storage resiliency need to go.
New, Open DPC++ Extensions Complement SYCL and C++
June 30, 2020 by

In this guest article, our friends at Intel discuss how accelerated computing has diversified over the past several years given advances in CPU, GPU, FPGA, and AI technologies. This innovation drives the need for an open and cross-platform language that allows developers to realize the potential of new hardware, minimizes development cost and complexity, and maximizes reuse of their software investments.
insideHPC Special Report: Citizens Benefit from Public/Private Partnerships – Part 3
June 29, 2020 by

This special report sponsored by Dell Technologies, takes a look at how now more than ever, agencies from all levels of government are teaming with private Information Technology (IT) organizations to leverage AI and HPC to create and implement solutions that not only increase safety for all, but also provide a more streamlined and modern experience for citizens.
insideHPC Special Report: Citizens Benefit from Public/Private Partnerships – Part 2
June 22, 2020 by
This special report sponsored by Dell Technologies, takes a look at how now more than ever, agencies from all levels of government are teaming with private Information Technology (IT) organizations to leverage AI and HPC to create and implement solutions that not only increase safety for all, but also provide a more streamlined and modern experience for citizens.
insideHPC Special Report: Citizens Benefit from Public/Private Partnerships
June 15, 2020 by
This special report sponsored by Dell Technologies, takes a look at how now more than ever, agencies from all levels of government are teaming with private Information Technology (IT) organizations to leverage AI and HPC to create and implement solutions that not only increase safety for all, but also provide a more streamlined and modern experience for citizens.
insideHPC Special Report: HPC and AI for the Era of Genomics
May 27, 2020 by

This special report sponsored by Dell Technologies, takes a deep dive into HPC and AI for life sciences in the era of genomics. The report also highlights a lineup of Ready Solutions created by Dell Technologies which are highly optimized and tuned hardware and software stacks for a variety of industries. The Ready Solutions for HPC Life Sciences have been designed to speed time to production, improve performance with purpose-built solutions, and scale easier with modular building blocks for capacity and performance.
How HPC is aiding the fight against COVID-19
May 14, 2020 by
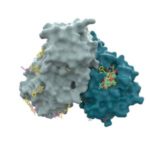
In this special guest feature, Dr. Rosemary Francis writes that HPC is playing a massive part in the fight against Covid-19 through modeling, genomics, and drug discovery. “Thanks to the work in labs and HPC centres around the world, we now know that the molecular mechanism of the SARS-CoV-2 entry is via a lock and key effect; a spike on the outside of the virus acts as a key to unlock an ACE2 receptor protein on the human cell.”
Novel Liquid Cooling Technologies for HPC
May 12, 2020 by

In this special guest feature, Robert Roe from Scientific Computing World writes that increasingly power-hungry and high-density processors are driving the growth of liquid and immersion cooling technology. “We know that CPUs and GPUs are going to get denser and we have developed technologies that are available today which support a 500-watt chip the size of a V100 and we are working on the development of boiling enhancements that would allow us to go beyond that.”
Slidecast: The Sad State of Affairs in HPC Storage (But there is light at the end of the tunnel)
May 6, 2020 by

In this video, Robert Murphy from Panasas describes the current state of the HPC storage market and how Panasas is stepping up with high performance products that deliver economical performance without risk. “According to a recent study published by Hyperion Research, total cost of ownership (TCO) now rivals performance as a top criterion for purchasing HPC storage systems. Newly retooled with COTS hardware and a unique architecture, Panasas delivers surprising performance at a lower TCO than competitive solutions.”

